在大数据分析和数据仓库设计中,星型模型和雪花模型是两种常用的建模方法,它们各有优缺点,适合不同的业务场景。从结构特点到实际应用,从查询性能到存储优化,如何选择合适的模型对提升数据处理效率至关重要。本篇文章将以详细的表格、案例分析和 SQL 示例,全面解析星型模型与雪花模型的核心概念、结构对比和应用场景,帮助读者掌握数据建模的关键技术。
星型模型
什么是星型模型
星型模型(Star Schema)是一种数据仓库设计方法,其结构像一颗星星:在模型的中心是一个存储事务数据的事实表,周围是与之相连的多个维度表。这种设计简单、直观,非常适合快速分析和报表生成。星型模型最常见于商业智能(BI)系统和联机分析处理(OLAP)场景。

星型模型的主要特征:
- 事实表存储度量指标,是模型的核心
- 维度表存储描述信息,为事实表提供上下文
星型模型的结构
事实表
事实表记录了与业务流程相关的度量数据或指标数据,并通过外键与维度表连接。其主要组成部分包括:
- 主键:唯一标识每条记录,一般由外键组成
- 外键:连接维度表的字段
- 度量指标:存储可以被分析和聚合的数据(如销售额、交易数量)
示例:销售事实表
| 销售ID | 时间ID | 产品ID | 地区ID | 销售额 |
|---|---|---|---|---|
| 1 | 101 | 501 | 301 | 100.00 |
| 2 | 102 | 502 | 302 | 200.00 |
- 销售ID:唯一标识每一笔销售记录
- 时间ID、产品ID、地区ID:外键,指向对应的维度表
- 销售额:存储度量数据,是主要的分析对象
维度表
维度表为事实表中的每条记录提供背景信息。这些信息用于分类、过滤和聚合数据。
示例:时间维度表
| 时间ID | 年 | 月 | 日 |
|---|---|---|---|
| 101 | 2023 | 1 | 1 |
| 102 | 2023 | 1 | 2 |
- 时间ID:主键,与事实表中的外键匹配
- 年、月、日:为时间维度提供细节
示例:产品维度表
| 产品ID | 产品名称 | 产品类别 |
|---|---|---|
| 501 | 手机 | 电子产品 |
| 502 | 笔记本电脑 | 电子产品 |
- 产品ID:主键,与事实表连接
- 产品名称:产品的具体名称
- 产品类别:产品所属类别,用于分组和分类
示例:地区维度表
| 地区ID | 地区名称 |
|---|---|
| 301 | 北京 |
| 302 | 上海 |
星型模型的设计流程
确定业务过程
确定需要支持的核心业务场景,例如:
- 零售业务中的销售、库存管理
- 银行业务中的交易分析
确定度量指标
提取需要分析的核心数据,如:
- 销售额、利润、交易量等
确定维度
定义与业务相关的维度,为数据提供上下文信息。例如:
- 时间维度:按年、月、日分析数据
- 产品维度:按类别、品牌分类数据
创建事实表和维度表
- 根据定义,设计事实表和维度表的结构
优化模型
- 确保维度表的主键唯一
- 在事实表的外键字段上添加索引
星型模型的优缺点
优点
缺点
星型模型的应用场景
零售行业
金融行业
医疗行业
星型模型的优化策略
索引优化
- 目标:提高查询效率
- 实现:在事实表的外键字段和维度表的主键字段上创建索引
- 示例:
CREATE INDEX idx_time_id ON 销售事实表(时间ID); CREATE INDEX idx_product_id ON 销售事实表(产品ID);
分区设计
- 目标:减少全表扫描,提高查询性能
- 策略:按时间、地区或类别对事实表分区
- 示例:将销售事实表按月份分区存储
CREATE TABLE 销售事实表_2023_01 AS SELECT * FROM 销售事实表 WHERE 时间ID BETWEEN '2023-01-01' AND '2023-01-31';
预计算聚合
- 目标:减少实时计算的压力
- 方法:提前计算常用的汇总数据存储为中间表
- 示例:预计算月销售额
CREATE TABLE 月销售汇总表 AS SELECT 年, 月, SUM(销售额) AS 总销售额 FROM 销售事实表 GROUP BY 年, 月;
混合设计
- 目标:兼顾简单性和灵活性
- 方法:对部分复杂的维度表采用雪花模型设计
- 场景:产品维度表过于庞大时,将 “类别” 和 “品牌” 分拆为独立表
案例分析与复杂 SQL 示例
案例:零售行业的月度销售报告
复杂 SQL 示例:多维分析
按 “时间” 和 “地区” 统计每月销售额:
SELECT T.年, T.月, R.地区名称, SUM(F.销售额) AS 总销售额 FROM 销售事实表 F INNER JOIN 时间维度表 T ON F.时间ID = T.时间ID INNER JOIN 地区维度表 R ON F.地区ID = R.地区ID GROUP BY T.年, T.月, R.地区名称 ORDER BY T.年, T.月, 总销售额 DESC;
雪花模型
什么是雪花模型
雪花模型(Snowflake Schema)是在星型模型基础上演化而来的数据仓库建模方法。与星型模型不同,雪花模型将维度表进一步标准化,将其拆分为多张关联的子表,从而形成类似雪花的多层次结构。
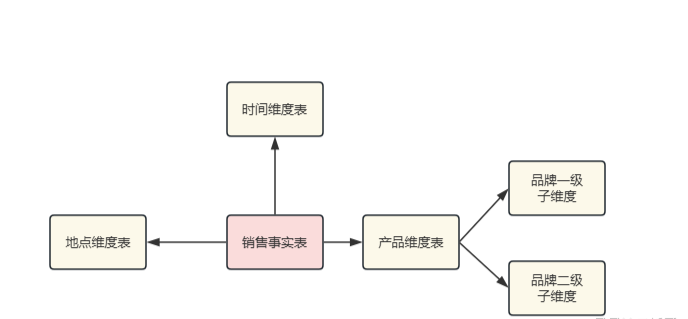
核心特点:
- 每个维度表被进一步拆分为多个表,减少数据冗余
- 子表通过外键连接,构成层级结构
- 查询复杂度增加,但存储空间更高效
雪花模型的结构
雪花模型由事实表和标准化维度表组成。以下是详细结构说明及示例。
事实表
事实表的结构与星型模型中类似,存储核心业务过程中的度量数据和外键字段。
示例:销售事实表
| 销售ID | 时间ID | 产品ID | 地区ID | 销售额 |
|---|---|---|---|---|
| 1 | 101 | 501 | 301 | 100.00 |
| 2 | 102 | 502 | 302 | 200.00 |
- 销售ID:唯一标识每一笔交易
- 时间ID、产品ID:外键,与标准化维度表关联
- 销售额:度量数据,用于业务分析
标准化维度表
在雪花模型中,每个维度表可能被进一步拆分。例如,“时间维度表” 可以被标准化为 “时间维度表” 和 “年份维度表”。
- 示例:时间维度表
| 时间ID | 年 | 月 | 日 |
|---|---|---|---|
| 101 | 2023 | 1 | 1 |
| 102 | 2023 | 1 | 2 |
- 示例:年份维度表
| 年份ID | 年 |
|---|---|
| 2023 | 2023 |
- 示例:产品维度表
| 产品ID | 类别ID | 产品类别 |
|---|---|---|
| 501 | 201 | 手机 |
| 502 | 202 | 笔记本电脑 |
- 示例:类别维度表
| 类别ID | 类别名称 |
|---|---|
| 201 | 电子产品 |
| 202 | 办公设备 |
通过这样的标准化设计,减少了 “类别名称” 等字段的重复存储,从而优化了存储空间。
雪花模型的设计流程
- 分析业务需求
明确数据仓库要支持的业务场景。例如,零售商可能希望分析产品类别的销售趋势。
- 标准化维度
根据维度表的属性,将重复字段分拆为子表。例如:
- 建立事实表
设计核心事实表,存储业务过程中的度量数据和维度外键。
- 验证模型设计
确保事实表与维度表的关系正确,维度表的主键与事实表外键一致。
雪花模型的优缺点
优点
缺点
雪花模型的应用场景
- 数据存储优化场景
当数据仓库存储空间有限,且维度表字段冗余较多时,雪花模型更为适合。
- 多层次维度分析场景
如果需要按层级结构进行分析(如产品类别、品牌、型号),雪花模型更能适应复杂的分析需求。
- 数据更新频繁的场景
在电商行业中,经常需要更新产品分类或品牌名称,雪花模型可以减少更新时的数据不一致问题。
雪花模型的优化策略
-- 预计算月度销售额 CREATE TABLE 月度销售汇总 AS SELECT 年, 月, 类别名称, SUM(销售额) AS 总销售额 FROM 销售事实表 F INNER JOIN 时间维度表 T ON F.时间ID = T.时间ID INNER JOIN 产品维度表 P ON F.产品ID = P.产品ID INNER JOIN 类别维度表 C ON P.类别ID = C.类别ID GROUP BY 年, 月, 类别名称;
星型模型与雪花模型的对比
在数据仓库建模中,星型模型和雪花模型是两种主要的设计方法。它们各有优缺点,适用于不同的业务场景和需求。以下将从多个维度对这两种模型进行详细对比,并提供相关实例和分析。
结构对比
星型模型结构
雪花模型结构
查询性能对比
| 特性 | 星型模型 | 雪花模型 |
|---|---|---|
| 查询复杂度 | 简单,关联表较少 | 复杂,多表关联增加 SQL 复杂度 |
| 查询性能 | 性能较高,适合频繁的聚合查询 | 性能较低,适合存储优化的场景 |
| 索引使用效率 | 索引容易配置,提高查询速度 | 需要更多索引支持,复杂性增加 |
存储需求对比
| 特性 | 星型模型 | 雪花模型 |
|---|---|---|
| 数据冗余 | 高 | 低 |
| 存储空间占用 | 较大 | 较小 |
| 数据一致性 | 容易产生冗余问题,数据一致性需监控 | 标准化设计,数据一致性较高 |
开发和维护成本对比
| 特性 | 星型模型 | 雪花模型 |
|---|---|---|
| 开发难度 | 低 | 高 |
| 维护成本 | 较低 | 较高 |
| 学习成本 | 易于理解,适合初学者 | 复杂结构,需要更高技能水平 |
适用场景对比
| 场景 | 星型模型 | 雪花模型 |
|---|---|---|
| 数据量 | 中小型数据量 | 大型或超大规模数据量 |
| 查询频率 | 高频查询 | 查询频率较低 |
| 报表需求 | 固定报表 | 灵活报表 |
| 维度层级复杂度 | 简单维度 | 多层次复杂维度 |
- 星型模型适用场景:快速开发数据分析系统。例如,一个零售商需要按地区和时间分析销售额,星型模型可以快速满足需求
- 雪花模型适用场景:大规模数据分析系统。例如,一个跨国电商平台需要支持多层级的产品分类和品牌分析,雪花模型更适合
综合对比与选择建议
根据实际需求选择合适的模型:
案例分析
零售商案例
电商平台案例
如何选择合适的模型
选择星型模型还是雪花模型,取决于业务需求、数据量、性能要求以及存储成本等多方面因素。本部分将通过决策流程、具体场景分析以及案例探讨如何选择合适的建模方法。
决策流程
评估业务需求
根据业务需求决定建模方向:
考虑数据规模
性能与成本权衡
场景分析
零售行业
- 需求:按时间、地区、产品分析销售额
- 数据量:中等,维度层级简单
- 模型选择:星型模型
- 理由:查询性能优先,报表需求固定,维度表结构简单
金融行业
- 需求:分析客户交易记录和风险评估
- 数据量:大,客户信息层次复杂
- 模型选择:雪花模型
- 理由:客户维度可能需要多层次描述(如账户类型、客户等级)
医疗行业
- 需求:按时间、科室、疾病统计就诊量
- 数据量:中等,维度层级较简单
- 模型选择:星型模型
- 理由:报表需求固定,查询性能优先
电商行业
- 需求:按时间、地区、品牌、产品类别分析销售额
- 数据量:超大规模,维度层级复杂
- 模型选择:雪花模型
- 理由:需要支持多层次维度分析,同时优化存储空间
综合对比分析
| 特性 | 星型模型 | 雪花模型 |
|---|---|---|
| 查询性能 | 高 | 较低 |
| 数据冗余 | 高 | 低 |
| 存储空间 | 较大 | 较小 |
| 维度复杂度 | 支持简单维度 | 支持多层次维度 |
| 开发难度 | 低 | 高 |
| 适用场景 | 报表固定、性能优先 | 存储优化、维度复杂 |
案例分析
零售商案例:快速销售报表生成
电商平台案例:复杂多层次分析
模型选择的混合使用
在实际场景中,可以结合星型模型和雪花模型的优势,采用混合建模方式。
方案设计
案例:大型零售商
选择模型的关键要点
明确核心需求
- 是以查询性能为优先,还是存储优化为目标
- 是报表需求固定,还是需要灵活多层次分析
根据业务规模调整
- 中小型业务:星型模型
- 大型业务或复杂层级:雪花模型
综合考虑维护和扩展
- 关注数据更新频率及系统扩展需求,选择更适合的模型
星型模型和雪花模型是数据仓库建模的两种经典方法,各有优缺点,适合不同的业务需求和数据规模。星型模型简单高效,适用于查询性能优先的场景;雪花模型结构严谨,适合复杂层级和存储优化。
参考资料
原创文章,转载请注明出处:http://www.opcoder.cn/article/91/