在当今的数据驱动时代,数据库的底层结构设计对于性能、存储效率以及处理各种应用场景的能力至关重要。在这篇文章中,我们将深入探讨列式存储(Column Store)与行式存储(Row Store)数据库表的特点,并借助真实世界的例子来比较它们的优缺点,以便更好地理解这些技术背后的逻辑与实践。
什么是列式存储与行式存储
列式存储(Column Store)与行式存储(Row Store)是数据库存储数据的两种不同方式。顾名思义,行式存储意味着数据按照每一行的方式存储,而列式存储则意味着数据按列来存储。
行式存储是一种非常直观的数据组织方式,每条记录(即每行)通常存储在一起,这种方式通常用于在线事务处理(OLTP)系统,因为它能方便地将所有与某一记录相关的数据快速取出。换句话说,行式存储更加符合人们直观的对表格数据的理解。
相比之下,列式存储将同一列的数据存储在一起,这种方式主要用于在线分析处理(OLAP)系统。列式存储更适合于需要对同一列进行大量聚合运算的场景,因为它能够有效地对某些特定列进行优化,从而减少 IO 开销。列式存储的设计理念与数据压缩、高效查询紧密相关,尤其是在大规模数据场景中,优势尤为突出。
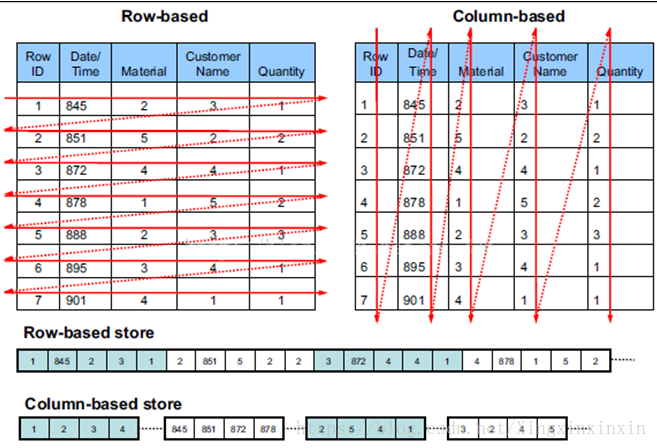
行式存储与列式存储的比较
在数据写入上的对比
-
行式存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
-
列式存储由于需要把一行记录拆分成单列保存,写入次数明显比行式存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行式存储在写入上占有很大的优势。
-
还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行式存储是在指定位置写入一次,列式存储是将磁盘定位到多个列上分别写入,这个过程仍是行式存储的数倍。所以,数据修改也是行式存储占优。
在数据读取上的对比
-
数据读取时,行式存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
-
列式存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
-
两种存储的数据分布。由于列式存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行式存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗 CPU,增加了解析的时间。所以,列式存储的解析过程更有利于分析大数据。
存储效率与压缩
列式存储在数据压缩方面有显著优势,因为列中的数据往往类型相似且范围相对集中,这使得它非常适合采用高效的压缩算法。举个例子,如果订单表中的订单日期列存储了相同或相近的日期信息,那么通过列式存储,可以轻松利用字典压缩或者运行长度编码来极大地减少存储空间的需求。这种压缩可以显著提高磁盘利用效率,尤其是对于历史数据量庞大的数据仓库系统。
相对的,行式存储的数据多样性较高,不同列的数据类型和内容差异较大,导致压缩的效率较低。因此,列式存储不仅能够提升查询效率,在磁盘占用和压缩效果方面也有着明显的优势。
应用场景
-
行式存储适用场景:在线事务处理系统(OLTP),例如银行的交易系统、电子商务网站的订单处理等。这些场景中,数据的插入和更新操作频繁,需要快速访问整行数据。
-
列式存储适用场景:在线分析处理系统(OLAP),例如商业智能(BI)系统、大数据分析等。这些场景通常需要对特定列进行聚合运算和大范围扫描,因此列式存储的性能优势非常明显。
实际案例分析
为了更好地理解列式存储与行式存储之间的差异,可以通过实际案例加以说明。著名的云计算服务提供商 Amazon Web Services(AWS)提供了 Amazon Redshift 这一数据仓库解决方案,Redshift 使用列式存储来实现高效的数据分析服务。通过列式存储的方式,Redshift 能够快速地处理大规模数据的聚合查询,显著提高了数据分析的效率。例如,在针对消费者购买行为的分析中,Redshift 可以快速聚合并计算所有订单的总销售额、平均消费水平等,从而帮助企业进行决策。
相对地,像 MySQL 这样的传统数据库管理系统则更偏向于行式存储。MySQL 非常适合应用于电商交易系统,能够高效处理单个订单的插入、查询、更新和删除操作。在一个典型的电子商务应用中,用户下单、修改订单信息、取消订单等操作频繁,行式存储的数据库能以较小的延迟响应这些请求,这是列式存储难以实现的。
列式存储的不足与改进
虽然列式存储在数据分析方面具有明显的优势,但它也存在一些不足之处。首先,对于频繁的插入和更新操作,列式存储的性能不如行式存储理想,因为每次插入或更新时,可能需要分别访问和修改多个列的数据,这会导致较大的操作开销。其次,列式存储的数据并不适合处理复杂的事务操作。在处理涉及多表的联结操作或需要维持数据一致性的复杂事务时,列式存储的实现会更加复杂,性能也较为有限。
为了弥补这些不足,一些现代的数据管理系统开始尝试结合列式存储和行式存储的优点。例如,Apache Cassandra 采用了一种混合的设计理念,结合了行式存储和列式存储的优势,从而能够在保证高吞吐的同时,提供灵活的数据查询能力。
另一个例子是 Google 的 Bigtable,Bigtable 采用了一种列族的概念,将相关的列分组存储,从而在保持一定列式存储效率的同时,减少了列与列之间的操作开销。
总结
列式存储和行式存储作为数据库底层的两种不同存储方式,各有其优势和劣势。它们分别适用于不同的场景:行式存储在事务处理、频繁插入和更新等操作中表现出色,而列式存储则在大规模数据分析和聚合查询中表现卓越。
参考资料
原创文章,转载请注明出处:http://www.opcoder.cn/article/80/