Oracle Database 10g 的一个新特性大大提高了搜索和处理字符数据的能力,这个特性就是正则表达式,Oracle 的正则表达式实现符合 IEEE 可移植操作系统接口(POSIX)正则表达式标准和 Unicode 联盟的 Unicode 正则表达式指南。
匹配字符
| 序号 | 字符 | 描述 |
| 1 | \d | 从0-9的任一数字 |
| 2 | \D | 任一非数字字符 |
| 3 | \w | 任一单词字符,包括A-Z、a-z、0-9和下划线 |
| 4 | \W | 任一非单词字符 |
| 5 | \s | 任一空白字符,包括制表符、换行符和回车符 |
| 6 | \S | 任一非空白字符 |
| 7 | . | 任一字符 |
| 8 | […] | 括号中的任一字符 |
| 9 | [^…] | 不在括号中的任一字符 |
- [...]
[abc] 将匹配一个单字符,a、b或c [a-z] 将匹配从a到z的任一字符
- [^...]
[^a-z] 将匹配不属于a-z的任一字符
字符簇
| 序号 | 字符 | 描述 |
| 1 | [[:alpha:]] | 任一字母 |
| 2 | [[:digit:]] | 任一数字 |
| 3 | [[:alnum:]] | 任一字母和数字 |
| 4 | [[:space:]] | 任一空白字符 |
| 5 | [[:upper:]] | 任一大写字母 |
| 6 | [[:lower:]] | 任一小写字母 |
| 7 | [[:punct:]] | 任一标点符号 |
| 8 | [[:xdigit:]] | 任一16进制的数字,相当于[0-9a-fA-F] |
重复字符
| 序号 | 字符 | 描述 |
| 1 | ? | 匹配前面的字符0次或1次 |
| 2 | + | 匹配前面的字符1次或多次 |
| 3 | * | 匹配前面的字符0次或多次 |
| 4 | {m} | 匹配前面的字符m次 |
| 5 | {m,} | 匹配前面的字符至少m次 |
| 6 | {m,n} | 匹配前面的字符至少m次,至多n次 |
定位字符
| 序号 | 字符 | 描述 |
| 1 | ^ | 随后的模式必须位于字符串的开始位置,如果是一个多行字符串,则必须位于行首 |
| 2 | $ | 前面的模式必须位于字符串的未端,如果是一个多行字符串,必须位于行尾 |
| 3 | \A | 前面的模式必须位于字符串的开始位置,忽略多行标志 |
| 4 | \z | 前面的模式必须位于字符串的未端,忽略多行标志 |
| 5 | \Z | 前面的模式必须位于字符串的未端,或者位于一个换行符前 |
| 6 | \b | 匹配一个单词边界,也就是一个单词字符和非单词字符中间的点 |
| 7 | \B | 匹配一个非单词字符边界位置,不是一个单词的词首 |
转义字符
| 序号 | 字符 | 描述 |
| 1 | \\ | 匹配字符 "\" |
| 2 | \. | 匹配字符 "." |
| 3 | \* | 匹配字符 "*" |
| 4 | \+ | 匹配字符 "+" |
| 5 | \? | 匹配字符 "?" |
| 6 | \| | 匹配字符 "|" |
| 7 | \( | 匹配字符 "(" |
| 8 | \) | 匹配字符 ")" |
| 9 | \{ | 匹配字符 "{" |
| 10 | \} | 匹配字符 "}" |
| 11 | \^ | 匹配字符 "^" |
| 12 | \$ | 匹配字符 "$" |
| 13 | \n | 匹配换行符 |
| 14 | \r | 匹配回车符 |
| 15 | \t | 匹配制表符 |
| 16 | \v | 匹配垂直制表符 |
正则表达式函数
REGEXP_LIKE
REGEXP_LIKE 类似于 LIKE 条件,只是 REGEXP_LIKE 执行正则表达式匹配,而不是 LIKE 执行的是简单模式匹配
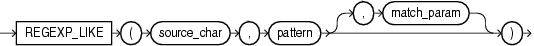
- 语法
REGEXP_LIKE(source_char, pattern[, match_param ])
- 参数
| 参数 | 描述 |
| source_char | 源字符串,可以是列名或者字符串常量、变量 |
| pattern | 正则表达式且长度限制在512字节内 |
| match_parameter | 一个文本串,允许用户设置该函数的匹配行为 |
- match_parameter 选项
| 选项值 | 描述 |
| C | 匹配时,大小写敏感,默认值 |
| I | 匹配时,大小写不敏感(忽略大小写) |
| N | 允许将 "." 作为通配符来匹配换行符 |
| M | 将源字符视为多行 |
- 例子 找出 first_name 字段以 "Ste" 开头以 "en" 结尾,中间是 "v" 或 "ph" 的记录
SELECT first_name, last_name FROM hr.employees WHERE REGEXP_LIKE(first_name, '^Ste(v|ph)en$') ORDER BY first_name, last_name; FIRST_NAME LAST_NAME -------------------- ------------------------- Stephen Stiles Steven King Steven Markle
找出 last_name 字段包含两个相邻的字符,且这些字符为 "a","e","i","o","u",不区分大小写
SELECT first_name, last_name FROM hr.employees WHERE REGEXP_LIKE (last_name, '([aeiou])\1', 'i') ORDER BY last_name; FIRST_NAME LAST_NAME -------------------- ------------------------- Harrison Bloom Lex De Haan Kevin Feeney Ki Gee Nancy Greenberg Danielle Greene Alexander Khoo David Lee 说明: 反向引用 "\1"
REGEXP_INSTR
REGEXP_INSTR 通过允许您搜索字符串以查找正则表达式模式,扩展了INSTR函数的功能。该函数使用输入字符集定义的字符计算字符串。它返回一个整数,表示匹配子字符串的开始或结束位置,具体取决于return_option参数的值。如果没有找到匹配,那么函数返回0
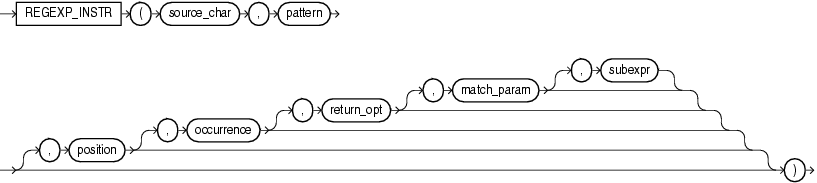
- 语法
REGEXP_INSTR(source_char, pattern[, position[, occurrence[, return_opt[, match_param[, subexpr]]]]]
- 参数
| 参数 | 描述 |
| source_char | 源字符串,可以是列名或者字符串常量、变量 |
| pattern | 正则表达式且长度限制在512字节内 |
| position | 表示开始匹配的位置,默认为1 |
| occurrence | 表示匹配的次数,默认为1 |
| return_option | 默认为0,表示 Oracle 返回出现的第一个字符的位置 |
| match_parameter | 一个文本串,允许用户设置该函数的匹配行为 |
- 例子 找出 ip 地址中,每个数字的位置
select
regexp_instr('192.168.0.1','\d',1,level) ind
from dual
connect by level <= 9;
IND
----------
1
2
3
5
6
7
9
11
0 -- 没有匹配到时返回为0
REGEXP_REPLACE
搜索并且替换匹配的正则表达式,如果第一个参数不是LOB,函数返回VARCHAR2; 如果第一个参数是LOB,函数返回CLOB。
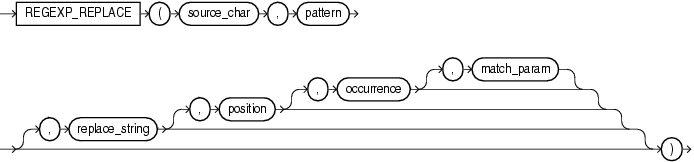
- 语法
REGEXP_REPLACE(source_char, pattern[, replace_string[,position[, occurrence[, match_param ]]]])
- 参数
| 参数 | 描述 |
| source_char | 源字符串,可以是列名或者字符串常量、变量 |
| pattern | 正则表达式且长度限制在512字节内 |
| replace_string | 指定用于替换的字符串 |
| position | 表示开始匹配的位置,默认为1 |
| occurrence | 指定替换出现的第 n 个字符串 |
| match_parameter | 一个文本串,允许用户设置该函数的匹配行为 |
- 例子 检查 phone_number字段,查找字符串 "xxx.xxx.xxxx",Oracle用 "(xxx) xxx-xxxx" 重新格式化此字符串
select
phone_number,
regexp_replace(phone_number, '(\d{3})\.(\d{3})\.(\d{4})', '(\1) \2-\3') "REGEXP_REPLACE"
from hr.employees where rownum <= 5
order by "REGEXP_REPLACE";
PHONE_NUMBER REGEXP_REPLACE
-------------------- --------------------
515.123.4444 (515) 123-4444
515.123.5555 (515) 123-5555
603.123.6666 (603) 123-6666
650.507.9833 (650) 507-9833
650.507.9844 (650) 507-9844
检查 country_name 字段,Oracle 在字符串中的每个非空字符后面加一个空格
select country_name, regexp_replace(country_name, '(.)', '\1 ') "REGEXP_REPLACE" from hr.countries where rownum <= 5; COUNTRY_NAME REGEXP_REPLACE ---------------------------------------- -------------------- Argentina A r g e n t i n a Australia A u s t r a l i a Belgium B e l g i u m Brazil B r a z i l Canada C a n a d a
检查字符串,查找两个或多个空格,Oracle 将两个或多个空格的出现替换为一个空格。
select
regexp_replace('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') "REGEXP_REPLACE"
from dual;
REGEXP_REPLACE
------------------------------------------------------------
500 Oracle Parkway, Redwood Shores, CA
REGEXP_SUBSTR
返回与给定模式匹配的字符串
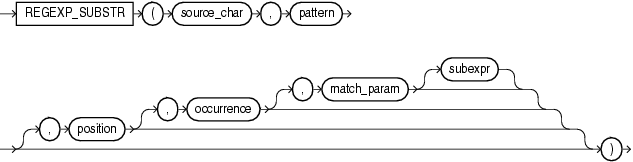
- 语法
REGEXP_SUBSTR(source_char, pattern[, position[, occurrence[, match_param[, subexpr]]]])
- 参数
| 参数 | 描述 |
| source_char | 源字符串,可以是列名或者字符串常量、变量 |
| pattern | 正则表达式且长度限制在512字节内 |
| position | 表示开始匹配的位置,默认为1 |
| occurrence | 出现的次数,默认为1 |
| match_parameter | 一个文本串,允许用户设置该函数的匹配行为 |
- 例子 检查字符串,查找以逗号为界且结尾为逗号的第一个子字符串
select
regexp_substr('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') "REGEXPR_SUBSTR"
from dual;
REGEXPR_SUBSTR
-----------------
, Redwood Shores,
检查字符串,查找 "http://" 后面跟一个或多个字母数字字符的子字符串,以及可选的句点"."
select
regexp_substr('http://www.example.com/products', 'http://([[:alnum:]]+\.?){3,4}/?') "REGEXP_SUBSTR"
from dual;
REGEXP_SUBSTR
-----------------------
http://www.example.com/
REGEXP_COUNT
返回给定模式在源字符串中出现的次数

- 语法
REGEXP_COUNT(source_char, pattern [, position [, match_param]])
- 参数
| 参数 | 描述 |
| source_char | 源字符串,可以是列名或者字符串常量、变量 |
| pattern | 正则表达式且长度限制在512字节内 |
| position | 表示开始匹配的位置,默认为1 |
| match_parameter | 一个文本串,允许用户设置该函数的匹配行为 |
- 例子 默认开始匹配的位置为1
select
regexp_count('123123123123123', '(12)3', 1, 'i') "REGEXP_COUNT" from dual;
REGEXP_COUNT
------------
5
修改匹配位置为3
select
regexp_count('123123123123', '123', 3, 'i') "COUNT"
from dual;
COUNT
----------
3
反向引用
反向引用是一个很有用的特性,它能够把子表达式的匹配部分保存在临时缓冲区中,供以后重用。缓冲区从左至右进行编号,并利用 \digit 符号进行访问。子表达式用一组圆括号来显示,利用反向引用可以实现较复杂的替换功能。
select
regexp_replace('Susan Mavris', '(.*) (.*)', '\2, \1') "REVERSED_NAME" from dual;
REVERSED_NAME
-------------
Mavris, Susan
参考资料
http://www.cnblogs.com/gkl0818/archive/2009/02/12/1389521.html
https://docs.oracle.com/cd/E11882_01/server.112/e41084/ap_posix.htm#SQLRF020
原创文章,转载请注明出处:http://www.opcoder.cn/article/8/