数据迭代和数据遍历都是按照某种顺序逐个对数据进行访问和操作,在 Python 中大多由 for 语句来引导。Pandas 中的迭代操作可以将数据按行或者按列遍历,我们可以进行更加细化、个性化的数据处理。
数据准备
- pyodps_iris
-- drop table pyodps_iris; create table if not exists pyodps_iris ( sepallength double comment '片长度(cm)', sepalwidth double comment '片宽度(cm)', petallength double comment '瓣长度(cm)', petalwidth double comment '瓣宽度(cm)', name string comment '种类' );
- 数据集
insert overwrite table pyodps_iris values (5.1,3.5,1.4,0.2,'Iris-setosa'), (4.9,3,1.4,0.2,'Iris-setosa'), (4.7,3.2,1.3,0.2,'Iris-setosa'), (4.6,3.1,1.5,0.2,'Iris-setosa'), (5,3.6,1.4,0.2,'Iris-setosa'), (5.4,3.9,1.7,0.4,'Iris-setosa'), (4.6,3.4,1.4,0.3,'Iris-setosa'), (5,3.4,1.5,0.2,'Iris-setosa'), (4.4,2.9,1.4,0.2,'Iris-setosa'), (4.9,3.1,1.5,0.1,'Iris-setosa'), (5.4,3.7,1.5,0.2,'Iris-setosa'), (4.8,3.4,1.6,0.2,'Iris-setosa'), (4.8,3,1.4,0.1,'Iris-setosa'), (4.3,3,1.1,0.1,'Iris-setosa'), (5.8,4,1.2,0.2,'Iris-setosa'), (5.7,4.4,1.5,0.4,'Iris-setosa'), (5.4,3.9,1.3,0.4,'Iris-setosa'), (5.1,3.5,1.4,0.3,'Iris-setosa'), (5.7,3.8,1.7,0.3,'Iris-setosa'), (5.1,3.8,1.5,0.3,'Iris-setosa'), (5.4,3.4,1.7,0.2,'Iris-setosa'), (5.1,3.7,1.5,0.4,'Iris-setosa'), (4.6,3.6,1,0.2,'Iris-setosa'), (5.1,3.3,1.7,0.5,'Iris-setosa'), (4.8,3.4,1.9,0.2,'Iris-setosa'), (5,3,1.6,0.2,'Iris-setosa'), (5,3.4,1.6,0.4,'Iris-setosa'), (5.2,3.5,1.5,0.2,'Iris-setosa'), (5.2,3.4,1.4,0.2,'Iris-setosa'), (4.7,3.2,1.6,0.2,'Iris-setosa'), (4.8,3.1,1.6,0.2,'Iris-setosa'), (5.4,3.4,1.5,0.4,'Iris-setosa'), (5.2,4.1,1.5,0.1,'Iris-setosa'), (5.5,4.2,1.4,0.2,'Iris-setosa'), (4.9,3.1,1.5,0.1,'Iris-setosa'), (5,3.2,1.2,0.2,'Iris-setosa'), (5.5,3.5,1.3,0.2,'Iris-setosa'), (4.9,3.1,1.5,0.1,'Iris-setosa'), (4.4,3,1.3,0.2,'Iris-setosa'), (5.1,3.4,1.5,0.2,'Iris-setosa'), (5,3.5,1.3,0.3,'Iris-setosa'), (4.5,2.3,1.3,0.3,'Iris-setosa'), (4.4,3.2,1.3,0.2,'Iris-setosa'), (5,3.5,1.6,0.6,'Iris-setosa'), (5.1,3.8,1.9,0.4,'Iris-setosa'), (4.8,3,1.4,0.3,'Iris-setosa'), (5.1,3.8,1.6,0.2,'Iris-setosa'), (4.6,3.2,1.4,0.2,'Iris-setosa'), (5.3,3.7,1.5,0.2,'Iris-setosa'), (5,3.3,1.4,0.2,'Iris-setosa'), (7,3.2,4.7,1.4,'Iris-versicolor'), (6.4,3.2,4.5,1.5,'Iris-versicolor'), (6.9,3.1,4.9,1.5,'Iris-versicolor'), (5.5,2.3,4,1.3,'Iris-versicolor'), (6.5,2.8,4.6,1.5,'Iris-versicolor'), (5.7,2.8,4.5,1.3,'Iris-versicolor'), (6.3,3.3,4.7,1.6,'Iris-versicolor'), (4.9,2.4,3.3,1,'Iris-versicolor'), (6.6,2.9,4.6,1.3,'Iris-versicolor'), (5.2,2.7,3.9,1.4,'Iris-versicolor'), (5,2,3.5,1,'Iris-versicolor'), (5.9,3,4.2,1.5,'Iris-versicolor'), (6,2.2,4,1,'Iris-versicolor'), (6.1,2.9,4.7,1.4,'Iris-versicolor'), (5.6,2.9,3.6,1.3,'Iris-versicolor'), (6.7,3.1,4.4,1.4,'Iris-versicolor'), (5.6,3,4.5,1.5,'Iris-versicolor'), (5.8,2.7,4.1,1,'Iris-versicolor'), (6.2,2.2,4.5,1.5,'Iris-versicolor'), (5.6,2.5,3.9,1.1,'Iris-versicolor'), (5.9,3.2,4.8,1.8,'Iris-versicolor'), (6.1,2.8,4,1.3,'Iris-versicolor'), (6.3,2.5,4.9,1.5,'Iris-versicolor'), (6.1,2.8,4.7,1.2,'Iris-versicolor'), (6.4,2.9,4.3,1.3,'Iris-versicolor'), (6.6,3,4.4,1.4,'Iris-versicolor'), (6.8,2.8,4.8,1.4,'Iris-versicolor'), (6.7,3,5,1.7,'Iris-versicolor'), (6,2.9,4.5,1.5,'Iris-versicolor'), (5.7,2.6,3.5,1,'Iris-versicolor'), (5.5,2.4,3.8,1.1,'Iris-versicolor'), (5.5,2.4,3.7,1,'Iris-versicolor'), (5.8,2.7,3.9,1.2,'Iris-versicolor'), (6,2.7,5.1,1.6,'Iris-versicolor'), (5.4,3,4.5,1.5,'Iris-versicolor'), (6,3.4,4.5,1.6,'Iris-versicolor'), (6.7,3.1,4.7,1.5,'Iris-versicolor'), (6.3,2.3,4.4,1.3,'Iris-versicolor'), (5.6,3,4.1,1.3,'Iris-versicolor'), (5.5,2.5,4,1.3,'Iris-versicolor'), (5.5,2.6,4.4,1.2,'Iris-versicolor'), (6.1,3,4.6,1.4,'Iris-versicolor'), (5.8,2.6,4,1.2,'Iris-versicolor'), (5,2.3,3.3,1,'Iris-versicolor'), (5.6,2.7,4.2,1.3,'Iris-versicolor'), (5.7,3,4.2,1.2,'Iris-versicolor'), (5.7,2.9,4.2,1.3,'Iris-versicolor'), (6.2,2.9,4.3,1.3,'Iris-versicolor'), (5.1,2.5,3,1.1,'Iris-versicolor'), (5.7,2.8,4.1,1.3,'Iris-versicolor'), (6.3,3.3,6,2.5,'Iris-virginica'), (5.8,2.7,5.1,1.9,'Iris-virginica'), (7.1,3,5.9,2.1,'Iris-virginica'), (6.3,2.9,5.6,1.8,'Iris-virginica'), (6.5,3,5.8,2.2,'Iris-virginica'), (7.6,3,6.6,2.1,'Iris-virginica'), (4.9,2.5,4.5,1.7,'Iris-virginica'), (7.3,2.9,6.3,1.8,'Iris-virginica'), (6.7,2.5,5.8,1.8,'Iris-virginica'), (7.2,3.6,6.1,2.5,'Iris-virginica'), (6.5,3.2,5.1,2,'Iris-virginica'), (6.4,2.7,5.3,1.9,'Iris-virginica'), (6.8,3,5.5,2.1,'Iris-virginica'), (5.7,2.5,5,2,'Iris-virginica'), (5.8,2.8,5.1,2.4,'Iris-virginica'), (6.4,3.2,5.3,2.3,'Iris-virginica'), (6.5,3,5.5,1.8,'Iris-virginica'), (7.7,3.8,6.7,2.2,'Iris-virginica'), (7.7,2.6,6.9,2.3,'Iris-virginica'), (6,2.2,5,1.5,'Iris-virginica'), (6.9,3.2,5.7,2.3,'Iris-virginica'), (5.6,2.8,4.9,2,'Iris-virginica'), (7.7,2.8,6.7,2,'Iris-virginica'), (6.3,2.7,4.9,1.8,'Iris-virginica'), (6.7,3.3,5.7,2.1,'Iris-virginica'), (7.2,3.2,6,1.8,'Iris-virginica'), (6.2,2.8,4.8,1.8,'Iris-virginica'), (6.1,3,4.9,1.8,'Iris-virginica'), (6.4,2.8,5.6,2.1,'Iris-virginica'), (7.2,3,5.8,1.6,'Iris-virginica'), (7.4,2.8,6.1,1.9,'Iris-virginica'), (7.9,3.8,6.4,2,'Iris-virginica'), (6.4,2.8,5.6,2.2,'Iris-virginica'), (6.3,2.8,5.1,1.5,'Iris-virginica'), (6.1,2.6,5.6,1.4,'Iris-virginica'), (7.7,3,6.1,2.3,'Iris-virginica'), (6.3,3.4,5.6,2.4,'Iris-virginica'), (6.4,3.1,5.5,1.8,'Iris-virginica'), (6,3,4.8,1.8,'Iris-virginica'), (6.9,3.1,5.4,2.1,'Iris-virginica'), (6.7,3.1,5.6,2.4,'Iris-virginica'), (6.9,3.1,5.1,2.3,'Iris-virginica'), (5.8,2.7,5.1,1.9,'Iris-virginica'), (6.8,3.2,5.9,2.3,'Iris-virginica'), (6.7,3.3,5.7,2.5,'Iris-virginica'), (6.7,3,5.2,2.3,'Iris-virginica'), (6.3,2.5,5,1.9,'Iris-virginica'), (6.5,3,5.2,2,'Iris-virginica'), (6.2,3.4,5.4,2.3,'Iris-virginica'), (5.9,3,5.1,1.8,'Iris-virginica');
迭代 Series
Series 本身是一个可迭代对象,可直接对 Series 使用 for 语句来遍历它的值。
import pandas as pd df = pd.DataFrame( [ ['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['name','team','Q1','Q2','Q3','Q4'] ) # 迭代指定的列 for i in df.name: print(i) # df.name.values 返回 array 结构数据可用于迭代;返回结果与上面的语句相同 for i in df.name.values: print(i)

迭代索引和指定的多列,使用 python 内置的 zip 函数将其打包为可迭代的 zip 对象。
import pandas as pd df = pd.DataFrame( [ ['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['name','team','Q1','Q2','Q3','Q4'] ) # 迭代索引和指定的两列 for i, n, q in zip(df.index, df.name, df.Q1): print(i, n, q)

from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(5).to_pandas() print(type(iris)) print('----------------------------------------------------') print(iris) print('----------------------------------------------------') for i in iris.name.values: print(i) print('----------------------------------------------------') for index, col1, col2 in zip(iris.index, iris.name, iris.sepallength): print(index, col1, col2)
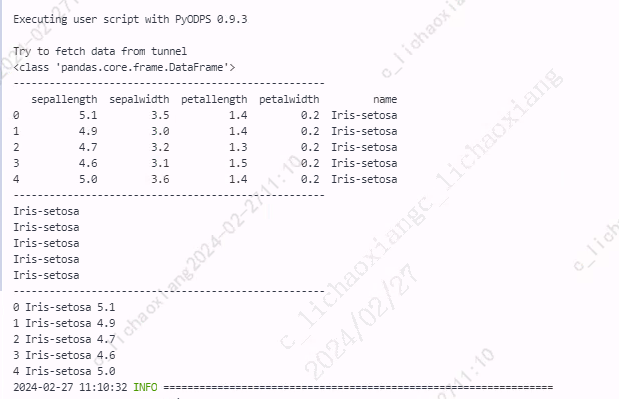
迭代 DataFrame
DataFrame 是 Pandas 库中最常用的数据结构之一,迭代 DataFrame 通常分为两种方式:按列迭代和按行迭代。
按列迭代指的是按照列的顺序逐个迭代 DataFrame 中的数据。可以使用 DataFrame 的 column 属性获取列名列表,并通过 for 循环遍历每个列名,然后再使用列名作为索引访问 DataFrame 的每列数据。
按行迭代指的是按照行的顺序逐个迭代 DataFrame 中的数据。可以使用 DataFrame 的 iterrows() 方法来实现迭代,该方法返回一个生成器,每次迭代返回一个元祖,其中包含行索引和行数据。
使用 Dataframe 的 index 属性
pandas.DataFrame.index 是 DataFrame 对象的属性,用于获取 DataFrame 的行索引。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(5).to_pandas() # 行索引 print(iris.index) # 按照行索引循环,获取 'name' 列和 'sepallength' 列 for i in iris.index: print(iris['name'][i], iris['sepallength'][i])

使用 DataFrame 的 loc 标签索引
loc 是 pandas.DataFrame 的一个属性,用于根据行/列标签从 DataFrame 中访问元素。
loc 以行标签和列标签作为参数,抽取整行或整列数据,当只有一个参数时,默认是行标签。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(5).to_pandas() for i in range(len(iris)): print(iris.loc[i, 'name'], iris.loc[i, 'sepallength'])

使用 DataFrame 的 iloc 位置索引
iloc 以行和列位置索引作为参数,0 表示第一行,1 表示第二行。抽取整行或整列数据,当只有一个参数时,默认是行索引。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(5).to_pandas() for i in range(len(iris)): print(iris.iloc[i, 4], iris.iloc[i, 0], iris.iloc[i, 2])
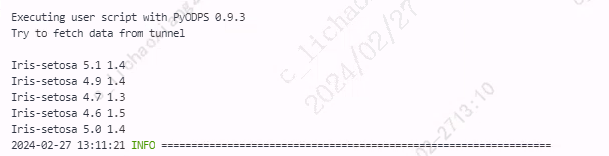
iteritems()
iteritems() 按列遍历,将 DataFrame 的每一列迭代为(列名, Series)对,可以通过 row[index] 对元素进行访问。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(3).to_pandas() for index, row in iris.iteritems(): # 输出每列列名 print(index) # 输出每列的值 print(row) # 仅输出每列第一行的值 print(row[0]) print('-----------------------')

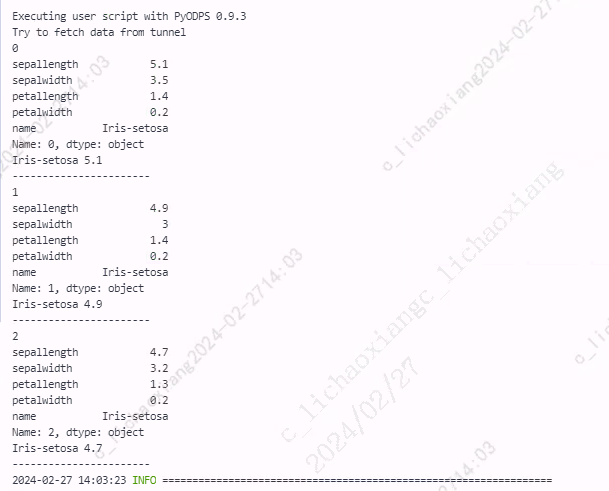
iterrows()
iterrows() 按行遍历,将 DataFrame 的每一行迭代为(index, Series)对,可以通过 row[name] 对元素进行访问。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(3).to_pandas() for index, row in iris.iterrows(): # 输出每行的索引值 print(index) # 输出每行的值 print(row) # 输出每一行 'name'、'sepallength' 两列的值 print(row['name'], row['sepallength']) print('-----------------------')
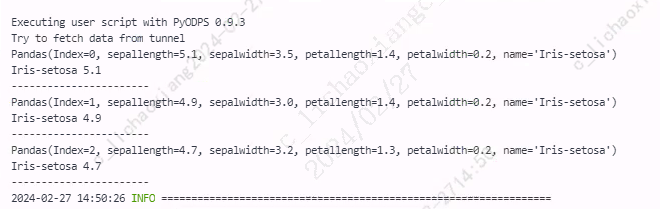
itertuples()
itertuples() 按行遍历,将 DataFrame 的每一行迭代为元祖,可以通过 row[name] 对元素进行访问,比 iterrows() 效率高。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(3).to_pandas() for row in iris.itertuples(): # 输出每行的值 print(row) # 输出每一行 'name'、'sepallength' 两列的值 print(getattr(row, 'name'), getattr(row, 'sepallength')) print('-----------------------')
循环更新值
iterrows() 方法逐行检索值,返回一个副本,而不是视图,因此更改 pandas.Series 不会更新原始数据。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(3).to_pandas() for index, row in iris.iterrows(): row['sepallength'] += row['sepallength'] print(iris)
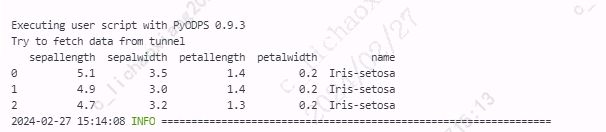
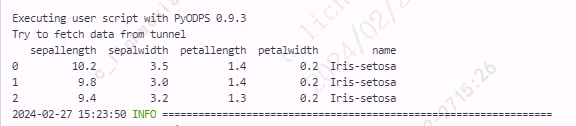
使用 at[] 选择并处理原始 DataFrame 中的数据,用于更新。
from odps import ODPS from odps.df import DataFrame import pandas as pd iris = o.get_table('pyodps_iris').to_df().head(3).to_pandas() for index, row in iris.iterrows(): iris.at[index, 'sepallength'] += row['sepallength'] print(iris)
应用案例
数据准备
- pyodps_fund_info
-- drop table if exists pyodps_fund_info; create table if not exists pyodps_fund_info ( fund_cd string comment '组合代码', fund_begin_dt date comment '成立日期', fund_mature_dt date comment '到期日期', settle_amount decimal comment '设立金额' ); insert overwrite table pyodps_fund_info values ('I33Q0001',date'2021-09-29',date'9999-12-31',400000000), ('I33Q0002',date'2021-09-07',date'9999-12-31',830000000), ('I33Q0003',date'2021-09-17',date'9999-12-31',300000000);
- pyodps_fund_inout
-- drop table pyodps_fund_inout; create table if not exists pyodps_fund_inout ( biz_dt date comment '业务日期', fund_cd string comment '组合代码', biz_type string comment '业务类别', amt decimal comment '金额' ); insert overwrite table pyodps_fund_inout values (date'2021-09-20','I33Q0002','OUT',3750000), (date'2021-09-22','I33Q0002','IN',12951891.31), (date'2021-09-24','I33Q0003','IN',0), (date'2021-09-29','I33Q0001','IN',150000000);
- pyodps_fund_total
-- drop table pyodps_fund_total; create table if not exists pyodps_fund_total ( biz_dt date comment '业务日期', fund_cd string comment '组合代码', subject_no string comment '自定义科目名称', subject_value decimal comment '科目金额' ); insert overwrite table pyodps_fund_total values (date'2021-09-30','I33Q0003','701A',299182787.46), (date'2021-09-30','I33Q0002','701A',831155793.7), (date'2021-09-30','I33Q0001','701A',400101279.4), (date'2021-09-17','I33Q0002','701A',831105793.7), (date'2021-09-17','I33Q0003','701A',301330045.17), (date'2021-09-16','I33Q0002','701A',831005267), (date'2021-09-07','I33Q0002','701A',830100526.7), (date'2021-09-08','I33Q0002','701A',830201053.4), (date'2021-09-25','I33Q0002','701A',830653160.2), (date'2021-09-25','I33Q0003','701A',300079063.88), (date'2021-09-22','I33Q0002','701A',831603398.85), (date'2021-09-22','I33Q0003','701A',299696786.97), (date'2021-09-24','I33Q0002','701A',830552633.5), (date'2021-09-24','I33Q0003','701A',300080846.49), (date'2021-09-28','I33Q0002','701A',830954740.3), (date'2021-09-23','I33Q0003','701A',301017785.14), (date'2021-09-23','I33Q0002','701A',830452106.8), (date'2021-09-26','I33Q0003','701A',300076938.51), (date'2021-09-26','I33Q0002','701A',830753686.9), (date'2021-09-27','I33Q0003','701A',300866289.99), (date'2021-09-27','I33Q0002','701A',830854213.6), (date'2021-09-28','I33Q0003','701A',301463332.77), (date'2021-09-09','I33Q0002','701A',830301580.1), (date'2021-09-10','I33Q0002','701A',830402106.8), (date'2021-09-11','I33Q0002','701A',830502633.5), (date'2021-09-12','I33Q0002','701A',830603160.2), (date'2021-09-14','I33Q0002','701A',830804213.6), (date'2021-09-13','I33Q0002','701A',830703686.9), (date'2021-09-15','I33Q0002','701A',830904740.3), (date'2021-09-18','I33Q0003','701A',301328857.37), (date'2021-09-18','I33Q0002','701A',831206320.4), (date'2021-09-19','I33Q0003','701A',301328999.57), (date'2021-09-19','I33Q0002','701A',831301818.75), (date'2021-09-29','I33Q0003','701A',297495756.72), (date'2021-09-29','I33Q0002','701A',831055267), (date'2021-09-29','I33Q0001','701A',400050639.7), (date'2021-09-20','I33Q0003','701A',301329141.77), (date'2021-09-20','I33Q0002','701A',831402345.45), (date'2021-09-21','I33Q0003','701A',301329284.04), (date'2021-09-21','I33Q0002','701A',831502872.15);
- 结果表 pyodps_fund_asset
-- drop table pyodps_fund_asset; create table if not exists pyodps_fund_asset ( biz_dt string comment '日期', fund_cd string comment '组合代码', biz_dt_ld string comment '上一日期', fund_begin_dt string comment '成立日期', assets_net_value decimal comment '资产净值', assets_share decimal comment '资产份额', unit_net_value decimal comment '单位净值', net_asset_inflow decimal comment '资金流入', net_asset_outflow decimal comment '资金流出' );
实现目标:根据组合成立当天的设立金额、每天的资产净值、每天的现金流,计算出每天的资产份额和单位净值。
计算公式:
- 当日资产份额 = (当日现金流入 - 当日现金流出) / 昨日单位净值 + 昨日资产份额
- 当日单位净值 = 当日资产净值 / 当日资产份额
注意事项:
- 折算出的每日资产份额保留两位小数;折算出的每日单位净值保留四位小数
- 成立日前一天的单位净值默认为1
PyODPS 3
- 通过 SQL 语句创建 Pandas DataFrame 对象
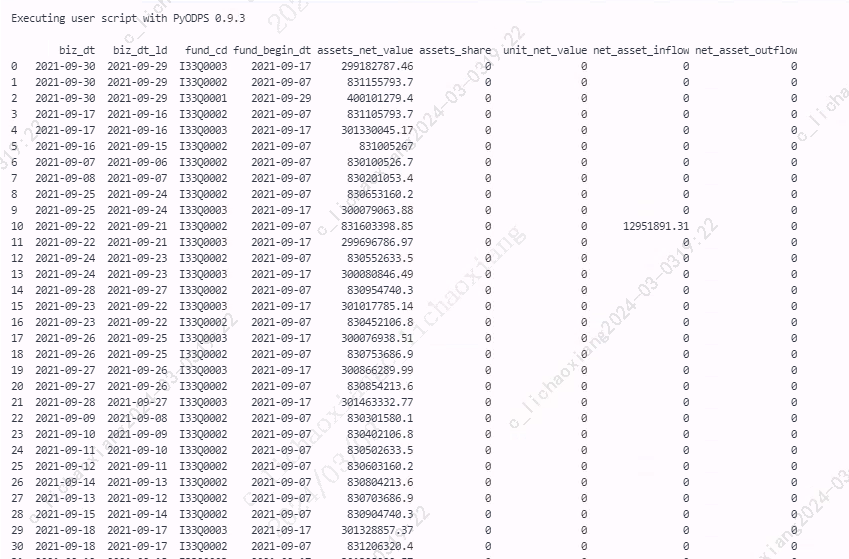
select to_char(a.biz_dt, 'yyyy-mm-dd') as biz_dt ,to_char(a.biz_dt - 1, 'yyyy-mm-dd') as biz_dt_ld ,a.fund_cd as fund_cd ,to_char(b.fund_begin_dt, 'yyyy-mm-dd') as fund_begin_dt ,round(a.subject_value, 2) as assets_net_value ,0 as assets_share ,0 as unit_net_value ,case when c.biz_type = 'IN' then nvl(c.amt, 0) else 0 end as net_asset_inflow ,case when c.biz_type = 'OUT' then nvl(c.amt, 0) else 0 end as net_asset_outflow from pyodps_fund_total a inner join pyodps_fund_info b on a.fund_cd = b.fund_cd left outer join pyodps_fund_inout c on a.fund_cd = c.fund_cd and a.biz_dt = c.biz_dt union all -- 初始化成立日前一天的数据 select to_char(b.fund_begin_dt - 1, 'yyyy-mm-dd') as biz_dt ,null as biz_dt_ld ,b.fund_cd as fund_cd ,to_char(b.fund_begin_dt, 'yyyy-mm-dd') as fund_begin_dt ,0 as assets_net_value ,b.settle_amount as assets_share ,1 as unit_net_value ,0 as net_asset_inflow ,0 as net_asset_outflow from pyodps_fund_info b
- 执行 SQL 语句,并转换为 Pandas DataFrame
df_source1 = o.execute_sql(u_sql).open_reader(tunnel=True).to_pandas() print(df_source1)
- 排序
df_source2 = df_source1.sort_values(by=['biz_dt', 'fund_cd'])
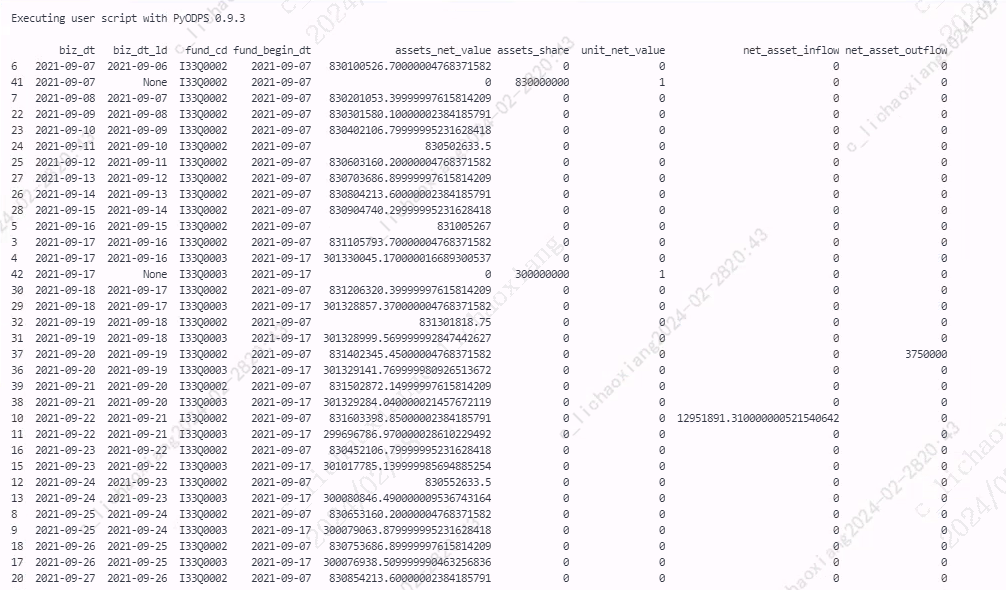
- 设置索引
df_source3 = df_source2.set_index(['biz_dt', 'fund_cd']) print(df_source3)
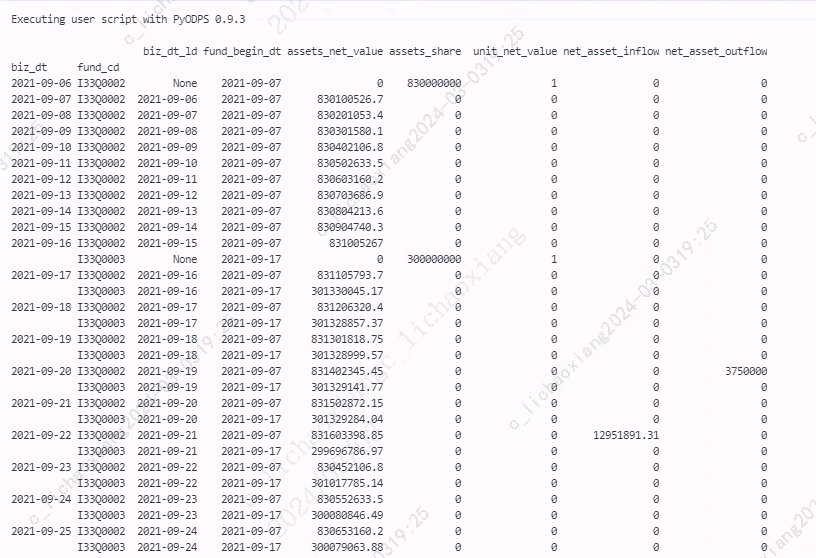
- 遍历每一行并更新数据
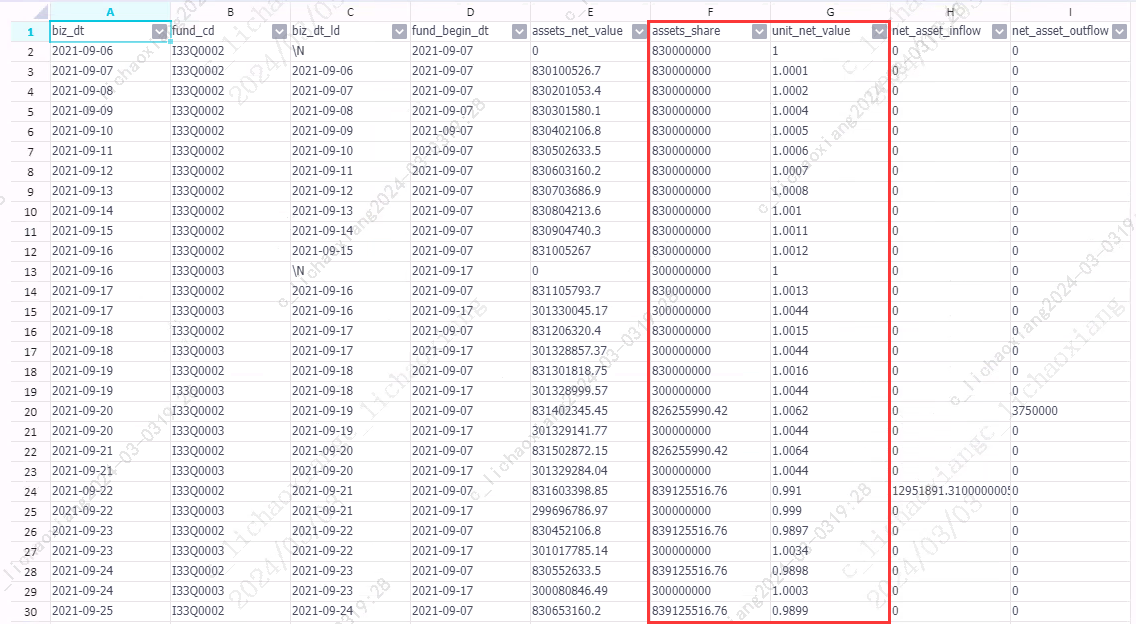
for index, row in df_source3.iterrows(): # 获取日期、组合代码 v_biz_dt = index[0] v_fund_cd = index[1] # 获取当日资产净值、当日流入、当日流出 v_assets_net_value = row['assets_net_value'] v_net_asset_inflow = row['net_asset_inflow'] v_net_asset_outflow = row['net_asset_outflow'] # 获取昨日日期 v_biz_dt_ld = row['biz_dt_ld'] # 获取昨日单位净值、昨日资产份额(昨日日期可能为 None,添加异常处理) try: v_unit_net_value_ld = df_source3.loc[(v_biz_dt_ld, v_fund_cd), 'unit_net_value'] v_assets_share_ld = df_source3.loc[(v_biz_dt_ld, v_fund_cd), 'assets_share'] except KeyError: print ('PyODPS Info: Index Not Fund') print ((v_biz_dt, v_biz_dt_ld, v_fund_cd)) continue # 获取当日资产份额、当日单位净值(计算时,使用 quantize 方法保留指定精度的小数位数) if float(nvl(v_unit_net_value_ld, 0)) == 0: v_assets_share = 0 else: v_assets_share = (float(v_net_asset_inflow) - float(v_net_asset_outflow)) / float(v_unit_net_value_ld) + float(v_assets_share_ld) v_assets_share = Decimal(v_assets_share).quantize(Decimal('0.00')) if float(nvl(v_assets_share, 0)) == 0: v_unit_net_value = 0 else: v_unit_net_value = float(v_assets_net_value) / float(v_assets_share) v_unit_net_value = Decimal(v_unit_net_value).quantize(Decimal('0.0000')) # 更新当日资产份额、当日单位净值 df_source3.loc[index, 'assets_share'] = v_assets_share df_source3.loc[index, 'unit_net_value'] = v_unit_net_value
- 重置索引
df = df_source3.reset_index()
- 转换为 ODPS Dataframe 对象
odps_df = DataFrame(df)
- 将数据写入结果表(insert overwrite 的方式)
odps_df.persist('pyodps_fund_asset', odps=o)
- 完整代码 PyODPS 3
import os from odps import ODPS from odps.df import DataFrame import pandas as pd import datetime from decimal import Decimal # 打开 Instance Tunnel 并关闭 limit 限制 options.tunnel.use_instance_tunnel = True options.tunnel.limit_instance_tunnel = False # 设置显示宽度 pd.set_option('display.width', 1000) def nvl(value, default): return value if value is not None else default # 日期格式转换为字符格式 u_sql = """ select to_char(a.biz_dt, 'yyyy-mm-dd') as biz_dt ,to_char(a.biz_dt - 1, 'yyyy-mm-dd') as biz_dt_ld ,a.fund_cd as fund_cd ,to_char(b.fund_begin_dt, 'yyyy-mm-dd') as fund_begin_dt ,round(a.subject_value, 2) as assets_net_value ,0 as assets_share ,0 as unit_net_value ,case when c.biz_type = 'IN' then round(nvl(c.amt, 0), 2) else 0 end as net_asset_inflow ,case when c.biz_type = 'OUT' then round(nvl(c.amt, 0), 2) else 0 end as net_asset_outflow from pyodps_fund_total a inner join pyodps_fund_info b on a.fund_cd = b.fund_cd left outer join pyodps_fund_inout c on a.fund_cd = c.fund_cd and a.biz_dt = c.biz_dt union all -- 初始化成立日前一天的数据 select to_char(b.fund_begin_dt - 1, 'yyyy-mm-dd') as biz_dt ,null as biz_dt_ld ,b.fund_cd as fund_cd ,to_char(b.fund_begin_dt, 'yyyy-mm-dd') as fund_begin_dt ,0 as assets_net_value ,b.settle_amount as assets_share ,1 as unit_net_value ,0 as net_asset_inflow ,0 as net_asset_outflow from pyodps_fund_info b """ # 执行 SQL 语句,并转换为 Pandas DataFrame df_source1 = o.execute_sql(u_sql).open_reader(tunnel=True).to_pandas() # 排序 df_source2 = df_source1.sort_values(by=['biz_dt', 'fund_cd']) # 设置索引 df_source3 = df_source2.set_index(['biz_dt', 'fund_cd']) # print(df_source3) # 遍历每一行数据 for index, row in df_source3.iterrows(): # 获取日期、组合代码 v_biz_dt = index[0] v_fund_cd = index[1] # 获取当日资产净值、当日流入、当日流出 v_assets_net_value = row['assets_net_value'] v_net_asset_inflow = row['net_asset_inflow'] v_net_asset_outflow = row['net_asset_outflow'] # 获取昨日日期 v_biz_dt_ld = row['biz_dt_ld'] # 获取昨日单位净值、昨日资产份额(昨日日期可能为 None,添加异常处理) try: v_unit_net_value_ld = df_source3.loc[(v_biz_dt_ld, v_fund_cd), 'unit_net_value'] v_assets_share_ld = df_source3.loc[(v_biz_dt_ld, v_fund_cd), 'assets_share'] except KeyError: print ('PyODPS Info: Index Not Fund') print ((v_biz_dt, v_biz_dt_ld, v_fund_cd)) continue # 获取当日资产份额、当日单位净值(计算时,使用 quantize 方法保留指定精度的小数位数) if float(nvl(v_unit_net_value_ld, 0)) == 0: v_assets_share = 0 else: v_assets_share = (float(v_net_asset_inflow) - float(v_net_asset_outflow)) / float(v_unit_net_value_ld) + float(v_assets_share_ld) v_assets_share = Decimal(v_assets_share).quantize(Decimal('0.00')) if float(nvl(v_assets_share, 0)) == 0: v_unit_net_value = 0 else: v_unit_net_value = float(v_assets_net_value) / float(v_assets_share) v_unit_net_value = Decimal(v_unit_net_value).quantize(Decimal('0.0000')) # 更新当日资产份额、当日单位净值 df_source3.loc[index, 'assets_share'] = v_assets_share df_source3.loc[index, 'unit_net_value'] = v_unit_net_value # 打印处理完成的结果集 # print(df_source3) # 重置索引 df = df_source3.reset_index() # print(df) # 转换为 ODPS DataFrame odps_df = DataFrame(df) # 将数据写入结果表(insert overwrite 的方式) odps_df.persist('pyodps_fund_asset', odps=o)
参考资料
深入浅出 Pandas > Pandas 高级操作 > 数据迭代
原创文章,转载请注明出处:http://www.opcoder.cn/article/71/