PyODPS 提供了 DataFrame API,它提供了类似 Pandas 的接口,但是能充分利用 MaxCompute 的计算能力。同时能在本地使用同样的接口,用 Pandas 进行计算。
数据准备
- pyodps_ml_100k_users
create table if not exists pyodps_ml_100k_users ( user_id BIGINT COMMENT '用户id', age BIGINT COMMENT '年龄', sex STRING COMMENT '性别', occupation STRING COMMENT '职业', zip_code STRING COMMENT '邮编' );
- pyodps_ml_100k_movies
CREATE TABLE IF NOT EXISTS pyodps_ml_100k_movies ( movie_id BIGINT COMMENT '电影 ID' ,title STRING COMMENT '电影标题' ,release_date STRING COMMENT '上映日期' ,video_release_date STRING COMMENT '视频发布日期' ,IMDb_URL STRING COMMENT 'IMDb 链接' ,unknown TINYINT COMMENT '未知' ,Action TINYINT COMMENT '动作' ,Adventure TINYINT COMMENT '冒险' ,Animation TINYINT COMMENT '动画' ,Children TINYINT COMMENT '儿童' ,Comedy TINYINT COMMENT '喜剧' ,Crime TINYINT COMMENT '犯罪' ,Documentary TINYINT COMMENT '纪录片' ,Drama TINYINT COMMENT '戏剧' ,Fantasy TINYINT COMMENT '奇幻' ,FilmNoir TINYINT COMMENT '黑色电影' ,Horror TINYINT COMMENT '恐怖' ,Musical TINYINT COMMENT '音乐' ,Mystery TINYINT COMMENT '悬疑' ,Romance TINYINT COMMENT '浪漫' ,SciFi TINYINT COMMENT '科幻' ,Thriller TINYINT COMMENT '惊悚' ,War TINYINT COMMENT '战争' ,Western TINYINT COMMENT '西部' );
- pyodps_ml_100k_ratings
CREATE TABLE IF NOT EXISTS pyodps_ml_100k_ratings ( user_id BIGINT COMMENT '用户id' ,movie_id BIGINT COMMENT '电影id' ,rating BIGINT COMMENT '得分' ,timestamp BIGINT COMMENT '时间戳' )
创建 DataFrame
在使用 DataFrame 时,需要了解 Collection(DataFrame)、Sequence 和 Scalar 三类对象的操作。三类对象分别表示表结构(或者二维结构)、列(一维结构)和标量。
使用 Pandas 创建的数据对象包含实际数据,但通过 MaxCompute 表创建的对象并不包含实际数据,仅包含对数据的操作。MaxCompute完成数据存储和计算。
从 MaxCompute 表创建 DataFrame
从 MaxCompute 表创建 DataFrame,需要将 Table 对象传入 DataFrame 方法,或者使用表的 to_df 方法。
- 传入 Table 对象
from odps.df import DataFrame users = DataFrame(o.get_table('pyodps_ml_100k_users')) print(users) print(users.execute())
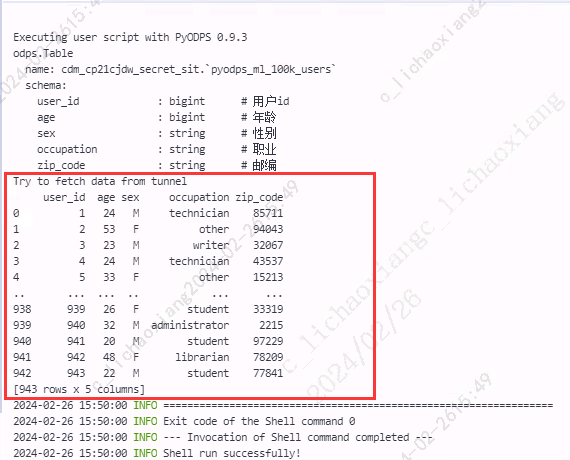
- 使用表的 to_df 方法
from odps.df import DataFrame users = o.get_table('pyodps_ml_100k_users').to_df()
从 MaxCompute 分区创建 DataFrame
从 MaxCompute 分区创建 DataFrame,需要将分区对象传入 DataFrame 方法,或者使用分区的 to_df 方法。
- 传入 Table 对象(分区表)
from odps.df import DataFrame pt_df = DataFrame(o.get_table('partitioned_table').get_partition('pt=20171111'))
- 使用表的 to_df 方法
from odps.df import DataFrame pt_df = o.get_table('partitioned_table').get_partition('pt=20171111').to_df()
从 Pandas DataFrame 创建 DataFrame
从 Pandas DataFrame 创建 DataFrame,需要将 Pandas DataFrame 对象传入 DataFrame 方法。
- 将 Pandas DataFrame 对象传入 DataFrame 方法
from odps.df import DataFrame import pandas as pd import numpy as np df = DataFrame(pd.DataFrame(np.arange(9).reshape(3, 3), columns=list('abc'))) print(df.dtypes) print(df.execute())
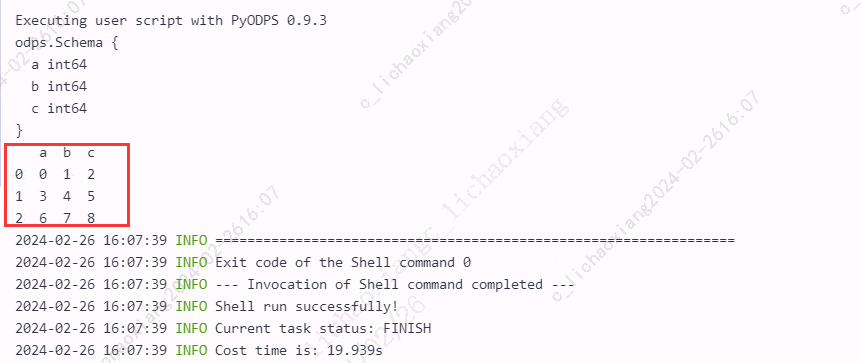
Sequence
SequenceExpr 代表二维数据集中的一列。SequenceExpr 只可以从一个 Collection 中获取,不支持手动创建 SequenceExpr。
- 使用 collection.column_name 取出一列, 代码示例如下:
print(iris.sepallength.head(5))
- 当列名存储在一个字符串变量中,可以使用 df[column_name] 实现取出一列,代码示例如下:
print(iris['sepallength'].head(5))
Collection
DataFrame 中所有二维数据集上的操作都属于 CollectionExpr,可视为一张 MaxCompute 表或一张电子表单,DataFrame 对象也是 CollectionExpr 的特例。CollectionExpr 中包含针对二维数据集的列操作、筛选、变换等大量操作。
获取类型
dtypes 可以用来获取 CollectionExpr 中所有列的类型,dtypes 返回的是 Schema 类型。
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df() print(iris.dtypes)
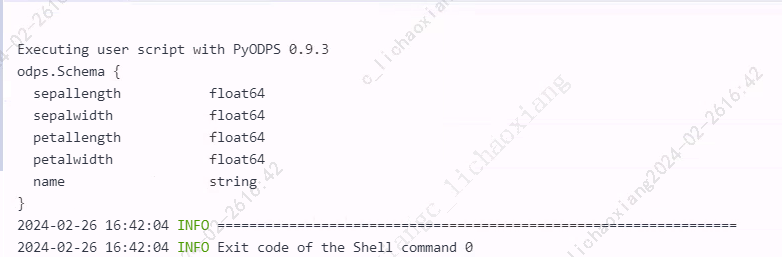
列选择
如果需要从一个 CollectionExpr 中选取部分列,产生新的数据集,可以使用 expr[columns] 语法。
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df() # 自动调用 execute 方法 print(iris['name', 'sepallength'].head(5)) # 需手动调用 execute 方法 print(iris['name', 'sepallength'].execute())

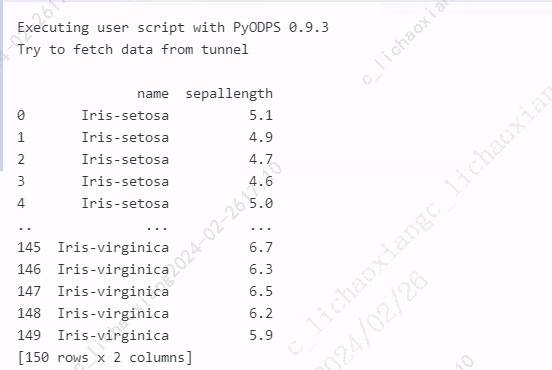
也可以使用如下方法。
print(iris[iris.name, iris.sepallength].execute())
注:如果只需要选取一列,需要在 Columns 后加上逗号或者显示标记为列表,例如 iris[iris.name, ]。
列删除
如果需要在新的数据集中排除已有数据集的某些列,可使用 exclude 方法。
print(iris.exclude('sepallength', 'petallength')[:5].head(5))
过滤数据
Collection 提供了数据过滤的功能。支持使用与(&) 、或(|)、非(~)、filter、Lambda 表达式,及其他多种查询方式对数据进行过滤。
- 查询 sepallength 大于5的数据
print(iris[iris.sepallength > 5].head(5))
- 与(&)条件
print(iris[(iris.sepallength < 5) & (iris['petallength'] > 1.5)].head(5))
- 或(|)条件
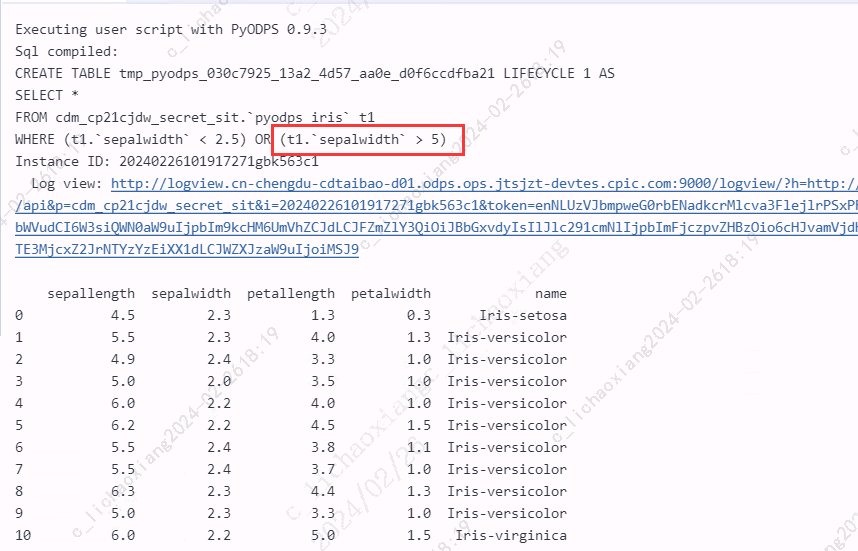
print(iris[(iris.sepalwidth < 2.5) | (iris.sepalwidth > 4)].head(5))
- 非(~)条件
print(iris[~(iris.sepalwidth > 3)].head(5))
- 显式调用 filter 方法,提供多个与条件
print(iris.filter(iris.sepalwidth > 3.5, iris.sepalwidth < 4).head(5))
- 使用 Pandas 中的 query 方法,通过查询语句做数据的筛选,在表达式中直接使用列名(如 sepallength)进行操作。在查询语句中,& 和 and 都表示与操作,| 和 or 都表示或操作
print(iris.query("(sepallength < 5) and (petallength > 1.5)").execute())
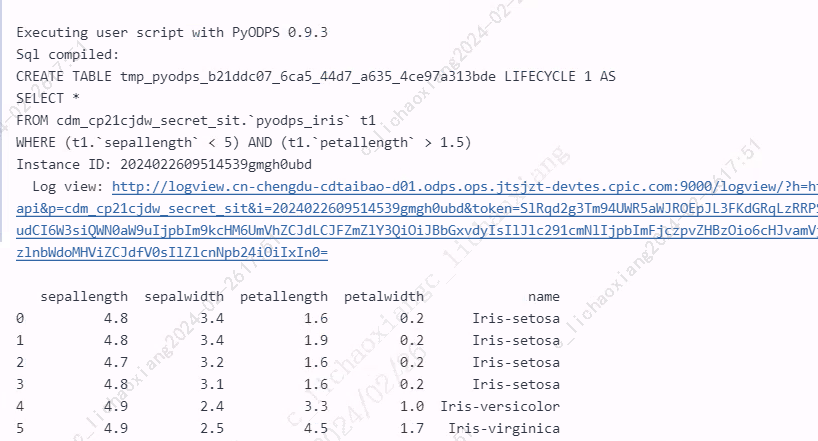
- 当表达式中需要使用到本地变量时,需要在该变量前加一个 @ 前缀
var = 5 print(iris.query("(sepalwidth < 2.5) | (sepalwidth > @var)").execute())
执行
延迟执行
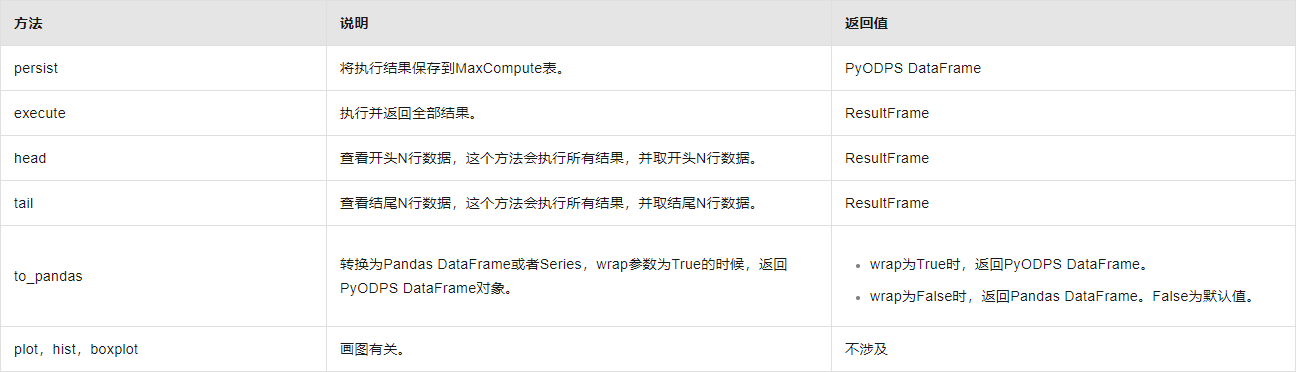
DataFrame 上的所有操作并不会立即执行,只有当显式调用 execute 方法,或者调用立即执行的方法时(内部调用的也是 execute),才会执行这些操作。
立即执行的方法如下图所示。
# 未手动调用 execute print(iris[iris.sepallength < 5][:5])

若未手动调用 execute,则打印 repr 对象,会显示整个抽象语法树。 如果需要执行,则必须手动调用 execute 方法。
读取执行结果
execute 或 head 函数输出的结果为 ResultFrame 类型,可从中读取结果。
ResultFrame 是结果集合,不能参与后续计算。
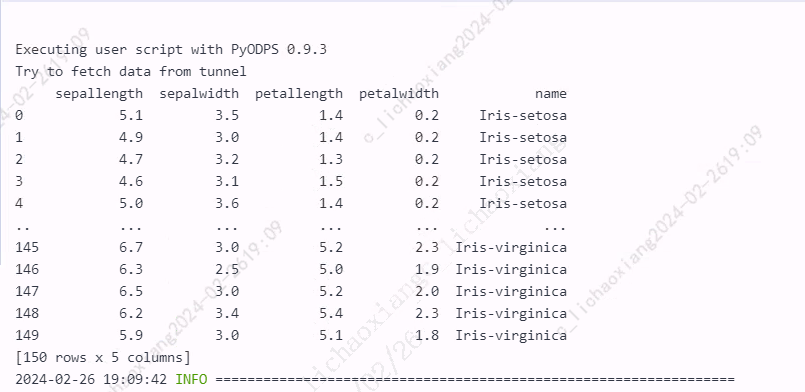
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df().execute() print(iris)
print(type(iris)

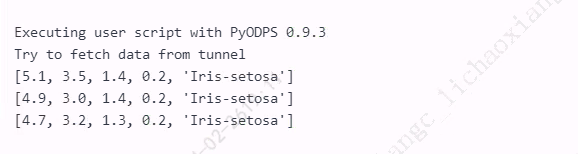
- ResultFrame 可以迭代取出每条记录
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df().head(3) for i in iris: print(list(i))
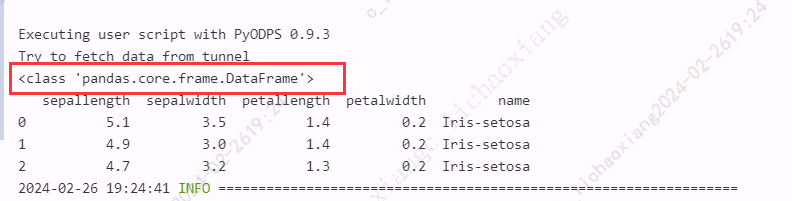
- 在安装有 Pandas 的前提下转换为 Pandas DataFrame
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df().head(3) pd_df = iris.to_pandas() print(type(pd_df)) print(pd_df)
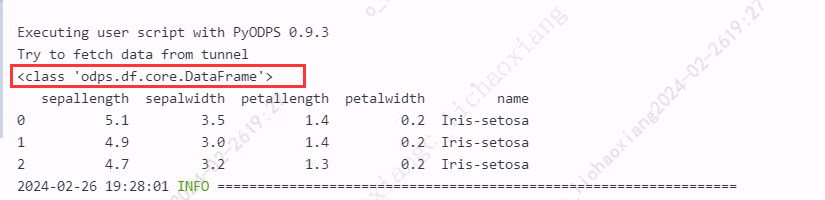
- 返回 PyODPS DataFrame 对象
from odps import ODPS from odps.df import DataFrame iris = o.get_table('pyodps_iris').to_df().head(3) wrapped_df = iris.to_pandas(wrap=True) print(type(wrapped_df)) print(wrapped_df)
保存执行结果为 MaxCompute 表
- 对于 Collection,可以调用 persist方法,用于返回一个新的 DataFrame 对象,参数为表名
iris2 = iris[iris.sepalwidth < 2.5].persist('pyodps_iris') print(iris2.head(5))
- persist 可以传入 partitions 参数,用于创建一个分区表。它的分区是 partitions 所指定的字段
iris3 = iris[iris.sepalwidth < 2.5].persist('pyodps_iris_test', partitions=['name']) print(iris3.data)
- 如果数据源中没有 ODPS 对象,例如数据源仅为 Pandas,在 persist 时需要手动指定 ODPS 入口对象,或者将需要的入口对象标明为全局对象。
# 指定入口对象 df.persist('table_name', odps=o)
保存执行结果为 Pandas DataFrame
可以使用 to_pandas 方法,如果 wrap 参数为 True,将返回 PyODPS DataFrame 对象。
- 使用 to_pandas 方法,返回 Pandas DataFrame 对象
print(type(iris[iris.sepalwidth < 2.5].to_pandas()))
返回结果:
<class 'pandas.core.frame.DataFrame'>
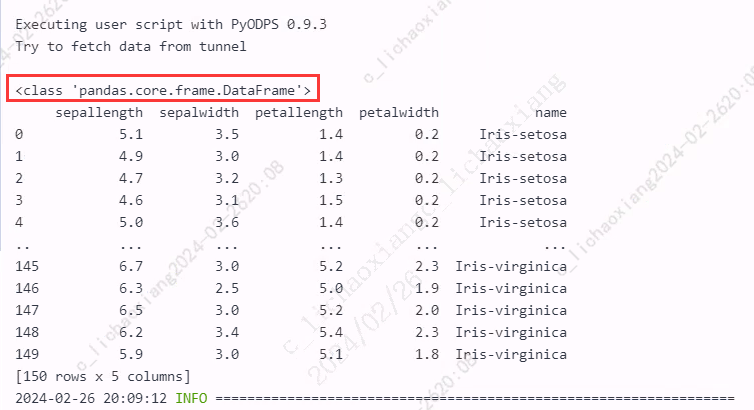
- 通过 odps sql 获取 Pandas DataFrame 对象
from odps import ODPS from odps.df import DataFrame with o.execute_sql('select * from pyodps_iris WHERE sepallength > 5').open_reader() as reader: pd_df = iris.to_pandas() print(type(pd_df)) print(pd_df)
- wrap 参数为 True,返回 PyODPS DataFrame 对象
print(type(iris[iris.sepalwidth < 2.5].to_pandas(wrap=True)))
返回结果:
<class 'odps.df.core.DataFrame'>
参考资料
DataFrame 概述Pandas高级操作--数据迭代
原创文章,转载请注明出处:http://www.opcoder.cn/article/67/