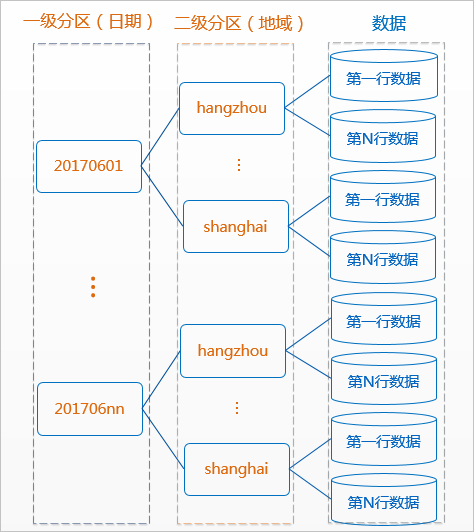
分区表是指拥有分区空间的表,即在创建表时指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,一个分区对应一个文件夹,文件夹下是对应分区所有的数据文件。
分区概述
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。
MaxCompute 将分区列的每个值作为一个分区(目录),可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过 WHERE 子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。使用数据时,如果指定需要访问的分区名称,则只会读取相应的分区。
使用限制
- 单表分区层级最多为 6 级
- 单表分区数最大值为 60000 个
- 单次查询允许查询最多的分区个数为 10000 个
- STRING 分区类型的分区值不支持使用中文
分区列的数据类型
MaxCompute 2.0 数据类型版本支持的分区字段为 TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
pt 是 STRING 类型,当 STRING 类型与 BIGINT(20170601)比较时,MaxCompute 会将二者转换为 DOUBLE 类型,此时有可能会有精度损失。
创建分区表
一级分区
- 创建一张只有一级分区的分区表
create table if not exists sale_detail1 ( shop_name string comment '', customer_id string comment '', total_price double comment '', region string comment '' ) comment 'table comment' partitioned by (sale_date string comment '一级分区字段');
二级分区
- 创建一张有二级分区的分区表
create table if not exists sale_detail2 ( shop_name string comment '', customer_id string comment '', total_price double comment '' ) comment 'table comment' partitioned by (sale_date string comment '一级分区字段', region string comment '二级分区字段');
查看分区信息
查看某个分区表具体的分区的信息。
desc <table_name> partition (<pt_spec>);
- table_name:必填。待查看分区信息的分区表名称
- pt_spec:必填。待查看的分区信息。格式为
partition_col1=col1_value1, partition_col2=col2_value1 ...对于有多级分区的表,必须指明全部的分区值。
SQL> desc sale_detail partition (sale_date='201310', region='beijing'); +------------------------------------------------------------------------------------+ | PartitionSize: 2109112 | +------------------------------------------------------------------------------------+ | CreateTime: 2015-10-10 08:48:48 | | LastDDLTime: 2015-10-10 08:48:48 | | LastModifiedTime: 2015-10-11 01:33:35 | +------------------------------------------------------------------------------------+ OK
列出所有分区
列出一张表中的所有分区,表不存在或为非分区表时,返回报错。
show partitions <table_name>;
- table_name:必填。待查看分区信息的分区表名称
SQL> show partitions sale_detail; sale_date=201310/region=beijing sale_date=201312/region=shenzhen sale_date=201312/region=xian sale_date=2014/region=shenzhen OK
分区操作
添加分区
为已存在的分区表新增分区。
限制条件
- 对于有多级分区的表,如果需要添加新的分区值,必须指明全部的分区
- 仅支持新增分区值,不支持新增分区字段
命令格式
alter table <table_name> add [if not exists] partition <pt_spec> [partition <pt_spec> partition <pt_spec> ...];
参数说明
- table_name:必填。待新增分区的分区表名称
- if not exists:可选。如果未指定 if not exists 而同名的分区已存在,会执行失败并返回报错
- 必填。新增的分区,格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)partition_col 是分区字段,partition_col_value 是分区值。分区字段不区分大小写,分区值区分大小写
使用示例
- 示例1:给表 sale_detail 添加一个分区,用来存储2013年12月杭州地区的销售记录
alter table sale_detail add if not exists partition (sale_date='201312', region='hangzhou');
- 示例2:给表 sale_detail 同时添加两个分区,用来存储2013年12月北京和上海地区的销售记录
alter table sale_detail add if not exists partition (sale_date='201312', region='beijing') partition (sale_date='201312', region='shanghai');
- 示例3:给表 sale_detail 添加分区,仅指定一个分区字段 sale_date,返回报错,需要同时指定2个分区字段 sale_date 和 region
alter table sale_detail add if not exists partition (sale_date='20111011');
删除分区
为已存在的分区表删除分区。
MaxCompute 支持通过条件筛选方式删除分区。如果希望一次性删除符合某个规则条件的多个分区,可以使用表达式指定筛选条件,通过筛选条件匹配分区并批量删除分区。
限制条件
- 每个分区过滤子句只能访问一个分区列
- 表达式用到的函数必须是内建的 Scalar 函数
注意事项
- 删除分区之后,MaxCompute 项目的存储量会降低
- 可以结合 MaxCompute 提供的生命周期功能,实现自动回收旧分区的能力
命令格式
- 未指定筛选条件
-- 一次删除一个分区 alter table <table_name> drop [if exists] partition <pt_spec>; -- 一次删除多个分区。 alter table <table_name> drop [if exists] partition <pt_spec>, partition <pt_spec>[, partition <pt_spec> ...];
- 指定筛选条件
alter table <table_name> drop [if exists] partition <partition_filtercondition>;
参数说明
- table_name:必填。待删除分区的分区表名称
- if exists:可选。如果未指定 if exists 且分区不存在,则返回报错
- pt_spec:必填。删除的分区。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col 是分区字段,partition_col_value 是分区值。分区字段不区分大小写,分区值区分大小写
使用示例
- 未指定筛选条件
-- 从表 sale_detail 中删除一个分区,2013年12月杭州分区的销售记录 alter table sale_detail drop if exists partition(sale_date='201312', region='hangzhou'); -- 从表 sale_detail 中同时删除两个分区,2013年12月杭州和上海分区的销售记录 alter table sale_detail drop if exists partition(sale_date='201312', region='hangzhou'), partition(sale_date='201312', region='shanghai');
- 指定筛选条件
-- 创建分区表 create table if not exists sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string); -- 添加分区 alter table sale_detail add if not exists partition (sale_date='201910') partition (sale_date='201911') partition (sale_date='201912') partition (sale_date='202001') partition (sale_date='202002') partition (sale_date='202003') partition (sale_date='202004') partition (sale_date='202005') partition (sale_date='202006') partition (sale_date='202007'); -- 批量删除分区 alter table sale_detail drop if exists partition(sale_date < '201911'); alter table sale_detail drop if exists partition(sale_date >= '202007'); alter table sale_detail drop if exists partition(sale_date like '20191%'); alter table sale_detail drop if exists partition(sale_date in ('202002', '202004', '202006')); alter table sale_detail drop if exists partition(sale_date between '202001' and '202007'); alter table sale_detail drop if exists partition(substr(sale_date, 1, 4) = '2020'); alter table sale_detail drop if exists partition(sale_date < '201912' or sale_date >= '202006'); alter table sale_detail drop if exists partition(sale_date > '201912' and sale_date <= '202004'); alter table sale_detail drop if exists partition(not sale_date > '202004'); -- 支持多个分区过滤表达式,表达式之间是 or 的关系 alter table sale_detail drop if exists partition(sale_date < '201911'), partition(sale_date >= '202007'); -- 添加其他格式分区 alter table sale_detail add if not exists partition (sale_date = '2019-10-05') partition (sale_date = '2019-10-06') partition (sale_date = '2019-10-07'); -- 批量删除分区,使用正则表达式匹配分区 alter table sale_detail drop if exists partition(sale_date rlike '2019-\\d+-\\d+'); -- 创建多级分区表 create table if not exists region_sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string , region string ); -- 添加分区 alter table region_sale_detail add if not exists partition (sale_date='201910', region='shanghai') partition (sale_date='201911', region='shanghai') partition (sale_date='201912', region='shanghai') partition (sale_date='202001', region='shanghai') partition (sale_date='202002', region='shanghai') partition (sale_date='201910', region='beijing') partition (sale_date='201912', region='beijing') partition (sale_date='202001', region='beijing') partition (sale_date='202002', region='beijing'); -- 执行如下语句批量删除多级分区,两个匹配条件是 or 的关系,会将 sale_date 小于 201911 或 region 等于 beijing 的分区都删除掉 alter table region_sale_detail drop if exists partition(sale_date<'201911'), partition(region='beijing'); -- 如果删除 sale_date 小于 201911且 region 等于 beijing 的分区,可以使用如下方法 alter table region_sale_detail drop if exists partition(sale_date<'201911', region='beijing');
修改分区的更新时间
MaxCompute SQL 提供 touch 操作,用于修改分区表中分区的 LastDataModifiedTime。此操作会将 LastDataModifiedTime 修改为当前时间。此时,MaxCompute 会认为数据有变动,重新计算生命周期。
使用限制
对于有多级分区的表,必须指明全部的分区。
命令格式
alter table <table_name> touch partition (<pt_spec>);
参数说明
- table_name:必填。待修改分区更新时间的分区表名称。如果表不存在,则返回报错
- pt_spec:必填。需要修改更新时间的分区信息。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)partition_col 是分区字段,partition_col_value 是分区值。如果指定的分区字段或分区值不存在,则返回报错
使用示例
-- 修改表 sale_detail 的分区 sale_date='201312', region='shanghai' 的 LastDataModifiedTime alter table sale_detail touch partition (sale_date='201312', region='shanghai');
修改分区值
MaxCompute SQL 支持通过 rename 操作更改分区表的分区值。
使用限制
- 不支持修改分区列的列名,只能修改分区列对应的值
- 对于有多级分区的表,必须指明全部的分区
命令格式
alter table <table_name> partition (<pt_spec>) rename to partition (<new_pt_spec>);
参数说明
- table_name:必填。待修改分区值的表名称
- pt_spec:必填。需要修改分区值的分区信息。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)partition_col 是分区字段,partition_col_value 是分区值。如果指定的分区字段或分区值不存在,则返回报错 - new_pt_spec:必填。修改后的分区信息。格式为
(partition_col1 = new_partition_col_value1, partition_col2 = new_partition_col_value2, ...)partition_col 是分区字段,new_partition_col_value 是新分区值
使用示例
-- 修改表 sale_detail 的分区值 alter table sale_detail partition (sale_date='201312', region='hangzhou') rename to partition (sale_date='201310', region='beijing');
合并分区
MaxCompute SQL 提供 merge partition 对分区表的分区进行合并,即将同一个分区表下的多个分区合并成一个分区,同时删除被合并的分区维度的信息,把数据移动到指定分区。
使用限制
- 不支持外部表,聚簇表合并后的分区会消除聚簇属性
- 一次性合并分区数量限制为 4000 个
命令格式
alter table <table_name> merge [if exists] partition (<predicate>) [, partition(<predicate2>) ...] overwrite partition (<fullpartitionSpec>) [purge];
参数说明
- table_name:必填。待合并分区的分区表名称
- if exists:可选。如果未指定 if exists,且分区不存在,会执行失败并返回报错。如果指定 if exists 后不存在满足 merge 条件的分区,则不生成新分区。如果运行过程中出现源数据被并发修改(包括 insert、rename 或 drop)时,即使指定 if exists 也会报错
- predicate:必填。筛选待合并分区需要满足的条件
- fullpartitionSpec:必填。目标分区信息
- purge:可选关键字。选择该字段,则会清理 session 目录,默认清理3天内的日志
使用示例
- 示例1:合并满足指定条件的分区到目标分区
-- 查看分区表的分区 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=00/mm=10 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10 -- 合并所有满足 hh='00' 的分区到 hh='00', mm='00' 中 alter table intpstringstringstring merge partition(hh='00') overwrite partition(ds='20181101', hh='00', mm='00'); -- 查看合并后的分区 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10
- 示例2:合并指定的多个分区到目标分区
-- 合并多个指定分区 alter table intpstringstringstring merge if exists partition(ds='20181101', hh='00', mm='00'), partition(ds='20181101', hh='10', mm='00'), partition(ds='20181101', hh='10', mm='10') overwrite partition(ds='20181101', hh='00', mm='00') purge; -- 查看分区表的分区 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00
清空分区数据
MaxCompute 支持通过条件筛选方式清空分区数据。如果希望一次性删除符合某个规则条件的一个或多个分区,可以使用表达式指定筛选条件,通过筛选条件匹配分区并批量清空分区数据。
命令格式
- 未指定筛选条件
truncate table <table_name> partition <pt_spec>[, partition <pt_spec>....];
- 指定筛选条件
truncate table <table_name> partition <partition_filtercondition>;
参数说明
- table_name:必填。待清空分区数据的分区表名称
- pt_spec:必填。待清空数据的分区。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)partition_col 是分区字段,partition_col_value 是分区值。分区字段不区分大小写,分区值区分大小写 - partition_filtercondition:指定筛选条件时必填。分区筛选条件,不区分大小写
使用示例
- 未指定筛选条件
-- 从表 sale_detail 中清空一个分区,清空2013年12月杭州地域的销售记录 truncate table sale_detail partition(sale_date='201312', region='hangzhou'); -- 从表 sale_detail 中同时清空两个分区,清空2013年12月杭州和上海地域的销售记录 truncate table sale_detail partition(sale_date='201312', region='hangzhou'), partition(sale_date='201312',region='shanghai');
- 指定筛选条件
-- 从表 sale_detail 中清空多个分区,清空杭州地域下 sale_date 以2013开头的销售记录 truncate table sale_detail partition(sale_date like '2013%' and region='hangzhou');
静态分区与动态分区
静态分区和动态分区是对应的,所谓静态分区就是指在写入分区表的时候要指定分区值,例如:
insert overwrite table sd_data_test partition (part='450', year='2017');
这里指定的 part 和 year 的值,写入分区之前要指定具体的分区值。动态分区在写入前时候不指定,写入时指定源表的一个字段(多级分区指定多个),那么在写入的时候相同的字段值会自动创建成一个分区。
假设有如下场景,用户有一年 12 个月的中国各个省份的数据资料。那想对这个表的数据进行分区,静态分区比较繁琐,可以使用动态分区。
- A 表是源表非分区表
create table a ( mon string, pro string, col1 string, col2 string, col3 datetime );
- B 表是分区表
create table b (
col1 string,
col2 string,
col3 datetime
)
partitioned by (month string, province string);
- 指定所有分区列,动态写入
insert overwrite table b partition (month, province) select col1, col2, col3, mon, pro from a;
- 仅指定一级分区列,动态写入
insert into table b partition(month='12', province) select col1, col2, col3, pro from a;
插入或覆写静态分区数据
MaxCompute 支持通过 insert into 或 insert overwrite 操作向静态分区中插入、更新数据。
- 示例1:执行 insert into 命令向分区表 sale_detail 中追加数据
-- 创建一张分区表 sale_detail create table if not exists sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string, region string); -- 向源表增加分区。 alter table sale_detail add partition (sale_date='2013', region='china'); -- 向源表追加数据 insert into sale_detail partition (sale_date='2013', region='china') values ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 开启全表扫描,仅此Session有效。执行 select 语句查看表 sale_detail 中的数据 set odps.sql.allow.fullscan=true; select * from sale_detail; -- 返回结果 +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
- 示例2:执行 insert overwrite 命令更新表 sale_detail_insert 中的数据
-- 创建目标表 sale_detail_insert,与 sale_detail 有相同的结构 create table sale_detail_insert like sale_detail; -- 给目标表增加分区 alter table sale_detail_insert add partition (sale_date='2013', region='china'); -- 从源表 sale_detail 中取出数据插入目标表 sale_detail_insert。注意不需要声明目标表字段,也不支持重排目标表字段顺序 -- 对于静态分区目标表,分区字段赋值已经在 partition() 部分声明,不需要在 select_statement 中包含,只要按照目标表普通列顺序查出对应字段,按顺序映射到目标表即可 -- 动态分区表则需要在 select 中包含分区字段 set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_insert partition (sale_date='2013', region='china') select shop_name, customer_id, total_price from sale_detail; -- 开启全表扫描,仅此 Session 有效。执行 select 语句查看表 sale_detail_insert 中的数据。 set odps.sql.allow.fullscan=true; select * from sale_detail_insert; --返回结果。 +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
- 示例3:向某个分区插入数据时,分区列不允许出现在 select 子句中。如下语句会返回报错,sale_date 和 region 为分区列,不允许出现在静态分区的 select 子句中
set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_insert partition (sale_date='2013', region='china') select shop_name, customer_id, total_price, sale_date, region from sale_detail; FAILED: ODPS-0130071:[1,24] Semantic analysis exception - wrong columns count 5 in data source, requires 3 columns (includes dynamic partitions if any)
- 示例4:partition 的值只能是常量,不可以为表达式
set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_insert partition (sale_date=datepart('2016-09-18 01:10:00', 'yyyy'), region='china') select shop_name, customer_id, total_price from sale_detail; FAILED: ODPS-0130161:[1,64] Parse exception - invalid token 'datepart'
插入或覆写动态分区数据
在使用 MaxCompute SQL 处理数据时,insert into 或 insert overwrite 语句中不直接指定分区值,只指定分区列名(分区字段)。分区列的值在 select 子句中提供,系统自动根据分区列的值将数据插入到相应分区。
注意事项
如果需要更新表数据到动态分区,需要注意:
- insert into partition 时,如果分区不存在,会自动创建分区
- 多个 insert into partition 作业并发时,如果分区不存在,优先执行成功的作业会自动创建分区,但只会成功创建一个分区
- 如果不能控制 insert into partition 作业并发,建议通过 alter table 命令提前创建分区
- 如果目标表有多级分区,在执行 insert 操作时,允许指定部分分区为静态分区,但是静态分区必须是高级分区
- 向动态分区插入数据时,动态分区列必须在 select 列表中,否则会执行失败
- 动态分区操作的 SQL 的运行效率可能会较低
命令格式
insert {into|overwrite} table <table_name> partition (<ptcol_name>[, <ptcol_name> ...]) <select_statement> from <from_statement>;
- table_name:必填。需要插入数据的目标表名
- ptcol_name:必填。目标表分区列的名称
- select_statement:必填。select 子句,从源表中查询需要插入目标表的数据。如果目标表只有一级动态分区,则 select 子句的最后一个字段值即为目标表的动态分区值。源表 select 的值和输出分区的值的关系是由字段顺序决定,并不是由列名称决定的。当源表的字段与目标表字段顺序不一致时,建议按照目标表顺序在 select_statement 语句中指定字段
- from_statement:必填。from 子句,表示数据来源。例如,源表名称
使用示例
- 示例1:将源表中的数据插入到目标表中。在运行 SQL 语句之前,您无法得知会产生哪些分区。只有在语句运行结束后,才能通过 region 字段产生的值确定产生的分区
-- 创建目标表 total_revenues create table total_revenues (revenue double) partitioned by (region string); -- 将源表 sale_detail 中的数据插入到目标表 total_revenues set odps.sql.allow.fullscan=true; insert overwrite table total_revenues partition(region) select total_price as revenue, region from sale_detail; -- 执行 show partitions 语句查看表 total_revenues 的分区 show partitions total_revenues; -- 返回结果。 region=china OK -- 开启全表扫描,仅此 Session 有效。执行 select 语句查看表 total_revenues 中的数据 set odps.sql.allow.fullscan=true; select * from total_revenues; --返回结果。 +------------+------------+ | revenue | region | +------------+------------+ | 100.1 | china | | 100.2 | china | | 100.3 | china | +------------+------------+
- 示例2:将源表中的数据插入到目标表中。多级分区,指定一级分区 sale_date
-- 创建目标表 sale_detail_dypart create table sale_detail_dypart like sale_detail; -- 指定一级分区,将数据插入目标表 set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_dypart partition (sale_date='2013', region) select shop_name, customer_id, total_price, region from sale_detail; -- 开启全表扫描,仅此 Session 有效。执行 select 语句查看表 sale_detail_dypart 中的数据 set odps.sql.allow.fullscan=true; select * from sale_detail_dypart; --返回结果。 +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
- 示例3:动态分区中,select_statement 字段和目标表动态分区的对应关系是由字段顺序决定,并不是由列名称决定的
-- 将源表 sale_detail 中的数据插入到目标表 sale_detail_dypart set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_dypart partition (sale_date, region) select shop_name, customer_id, total_price, sale_date, region from sale_detail; -- 开启全表扫描,仅此 Session 有效。执行 select 语句查看表 sale_detail_dypart 中的数据 set odps.sql.allow.fullscan=true; select * from sale_detail_dypart; --返回结果。决定目标表 sale_detail_dypart 动态分区的字段 sale_date 为源表 sale_detail 的字段 sale_date;决定目标表 sale_detail_dypart 动态分区的字段 region 为源表 sale_detail 的字段 region +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+ -- 将源表 sale_detail 中的数据插入到目标表 sale_detail_dypart,调整 select 字段顺序 set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_dypart partition (sale_date, region) select shop_name, customer_id, total_price, region, sale_date from sale_detail; --开启全表扫描,仅此 Session 有效。执行 select 语句查看表 sale_detail_dypart 中的数据 set odps.sql.allow.fullscan=true; select * from sale_detail_dypart; --返回结果。决定目标表 sale_detail_dypart 动态分区的字段 sale_date为源表sale_detail 的字段 region;决定目标表 sale_detail_dypart 动态分区的字段 region 为源表 sale_detail 的字段 sale_date +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | china | 2013 | | s2 | c2 | 100.2 | china | 2013 | | s3 | c3 | 100.3 | china | 2013 | +------------+-------------+-------------+------------+------------+
- 示例4:向动态分区插入数据时,动态分区列必须在 select 列表中,否则会执行失败
set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_dypart partition (sale_date='2013', region) select shop_name, customer_id, total_price from sale_detail; FAILED: ODPS-0130071:[1,24] Semantic analysis exception - wrong columns count 3 in data source, requires 4 columns (includes dynamic partitions if any)
- 示例5:向动态分区插入数据时,不能仅指定低级子分区,而动态插入高级分区,否则会执行失败
-- sale_date 为一级分区字段,region 为二级分区字段 set odps.sql.allow.fullscan=true; insert overwrite table sale_detail_dypart partition (region='china', sale_date) select shop_name, customer_id, total_price, sale_date from sale_detail_dypart; FAILED: ODPS-0130071:[1,70] Semantic analysis exception - partition columns in partition specification are not the same as that defined in the table schema. The names and orders have to be exactly the same. Partition columns in the table schema are: (sale_date, region), while the partitions specified in the query are: (region, sale_date).
- 示例6:MaxCompute 在向动态分区插入数据时,如果分区列的类型与对应 select 中列的类型不严格一致,会隐式转换
-- 创建源表 src create table src (c int, d string) partitioned by (e int); -- 向源表 src 增加分区 alter table src add if not exists partition (e=201312); -- 向源表 src 追加数据 insert into src partition (e=201312) values (1,100.1), (2,100.2), (3,100.3); -- 创建目标表 parttable create table parttable(a int, b double) partitioned by (p string); -- 将源表 src 数据插入目标表 parttable set odps.sql.allow.fullscan=true; insert into parttable partition (p) select c, d, current_timestamp() from src; -- 查询目标表 parttable set odps.sql.allow.fullscan=true; select * from parttable; --返回结果如下。 +------------+------------+------------+ | a | b | p | +------------+------------+------------+ | 1 | 100.1 | 2020-11-25 15:13:28.686 | | 2 | 100.2 | 2020-11-25 15:13:28.686 | | 3 | 100.3 | 2020-11-25 15:13:28.686 | +------------+------------+------------+
注: 如果数据是有序的,动态分区插入会把数据随机打散,导致压缩率较低。
分区裁剪
MaxCompute 分区表是指在创建表时指定分区空间,即指定表内的几个字段作为分区列。使用数据时,如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高处理效率,降低费用。
分区裁剪是指对分区列指定过滤条件,使得 SQL 执行时只用读取表分区的部分数据,避免全表扫描引起的数据错误及资源浪费。但是分区失效的情况会经常发生。
判断分区裁剪是否生效
通过 EXPLAIN 命令查看 SQL 执行计划,用于判断 SQL 中的分区裁剪是否生效。
- 分区裁剪未生效
-- 创建分区表 create table if not exists sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string); -- 添加分区 alter table sale_detail add if not exists partition (sale_date='201910') partition (sale_date='201911') partition (sale_date='201912') partition (sale_date='202001') partition (sale_date='202002') partition (sale_date='202003') partition (sale_date='202004') partition (sale_date='202005') partition (sale_date='202006') partition (sale_date='202007'); -- 查看执行计划 set odps.sql.allow.fullscan=true; explain select shop_name, customer_id from sale_detail where sale_date = rand();
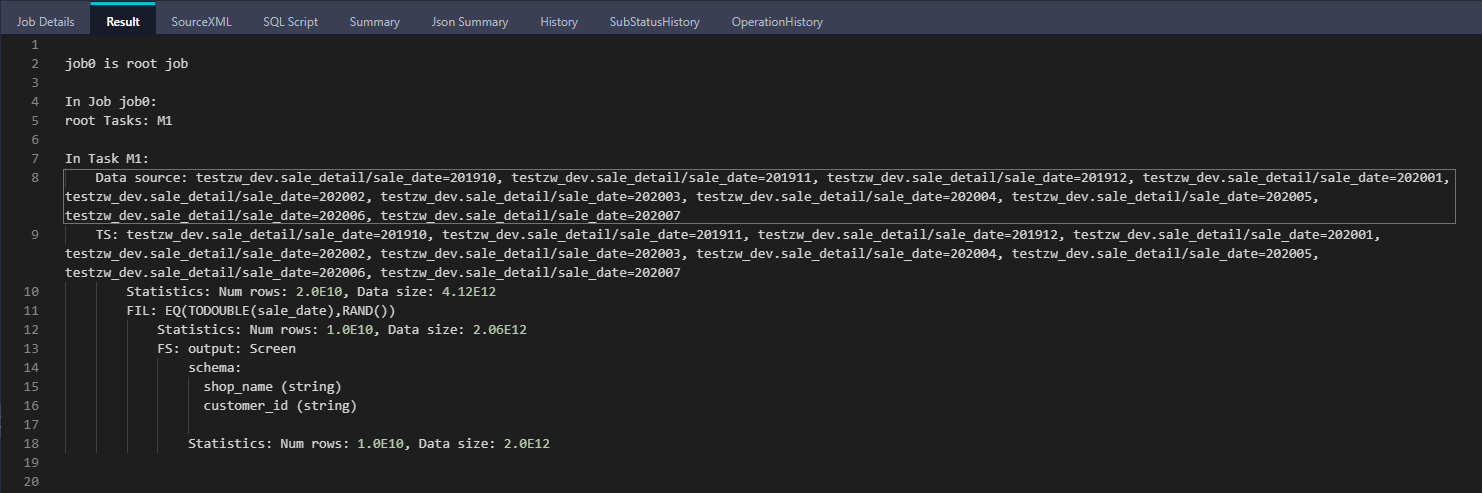
从执行计划中可见,SQL 读取了该表的所有分区。
- 分区裁剪生效
-- 查看执行计划 explain select shop_name, customer_id from sale_detail where sale_date = '202003';
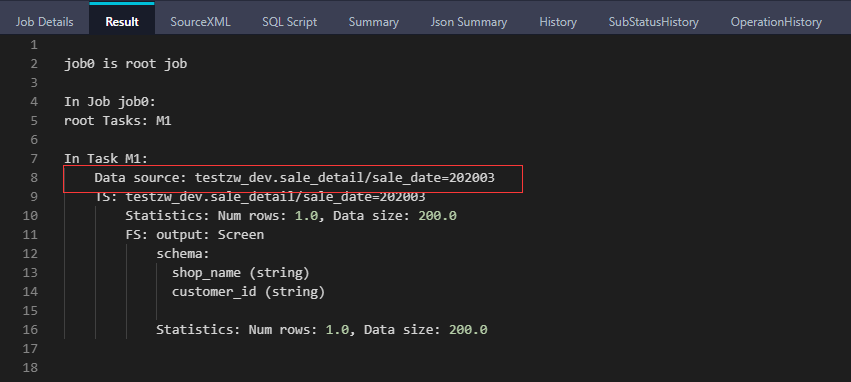
从执行计划中可见,SQL 只读取了表的 '202003' 分区。
分区裁剪失效的场景分析
a. 自定义函数导致分区裁剪失效
当分区裁剪的条件中使用了用户自定义函数(或者部分内建函数)时,分区裁剪失效。所以,对于分区值的限定,如果使用了非常规函数,建议使用 Explain 命令查看执行计划,确定分区裁剪是否生效。
explain
select ...
from xxxxx_base2_brd_ind_cw
where ds = concat(SPLIT_PART(bi_week_dim(' ${bdp.system.bizdate}'), ',', 1), SPLIT_PART(bi_week_dim(' ${bdp.system.bizdate}'), ',', 2));
b. 使用 JOIN 时分区裁剪失效
在 SQL 语句中使用 JOIN 进行关联时:
- 如果分区裁剪条件放在 WHERE 子句中,则分区裁剪会生效
- 如果分区裁剪条件放在 ON 子句中,从表的分区裁剪会生效,主表则不会生效
-- 创建分区表 create table if not exists sales ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string); -- 添加分区 alter table sales add if not exists partition (sale_date='201910') partition (sale_date='201911') partition (sale_date='201912') partition (sale_date='202001') partition (sale_date='202002') partition (sale_date='202003') partition (sale_date='202004') partition (sale_date='202005') partition (sale_date='202006') partition (sale_date='202007');
下面针对四种 JOIN 具体说明:
a. INNER JOIN
- 分区剪裁条件均放在 ON 子句中
set odps.sql.allow.fullscan=true; explain select a.customer_id, a.shop_name from sales a inner join sale_detail b on a.customer_id = b.customer_id and a.sale_date = '202003' and b.sale_date = '202003';
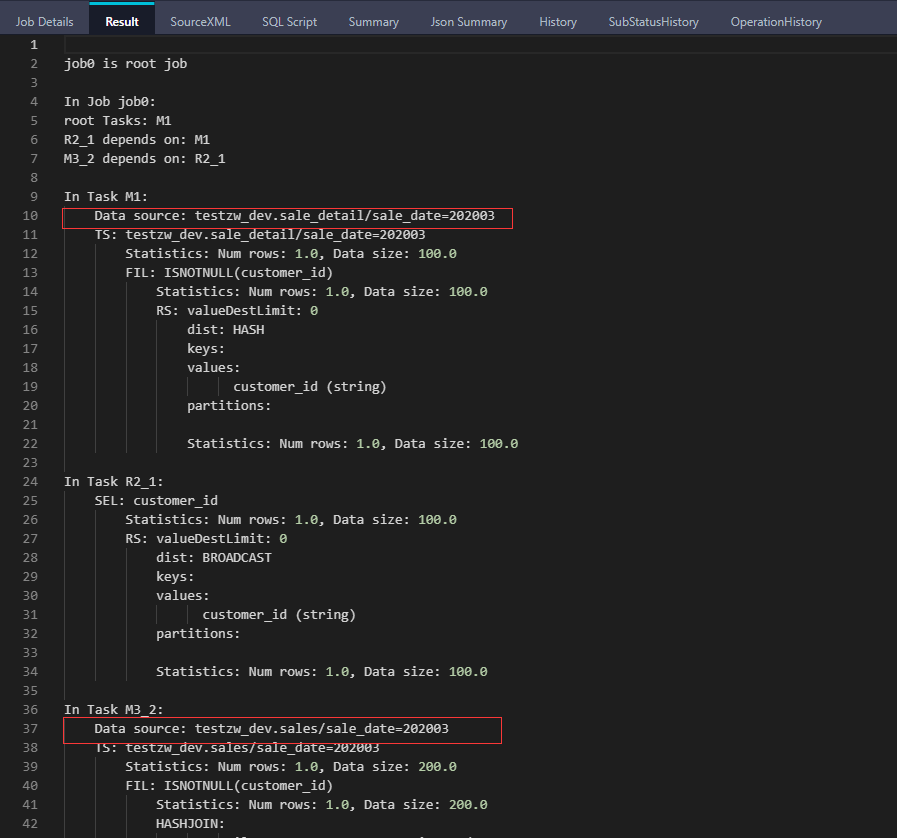
从执行计划中可见,两张表的分区裁剪都有效果。即:在 INNER JOIN 关联下,分区裁剪条件均放在 ON 子句或 WHERE 子句中,分区裁剪都有效果。
b. LEFT OUTER JOIN
- 分区剪裁条件均放在 ON 子句中
set odps.sql.allow.fullscan=true; explain select a.customer_id, a.shop_name from sales a left outer join sale_detail b on a.customer_id = b.customer_id and a.sale_date = '202003' and b.sale_date = '202003';
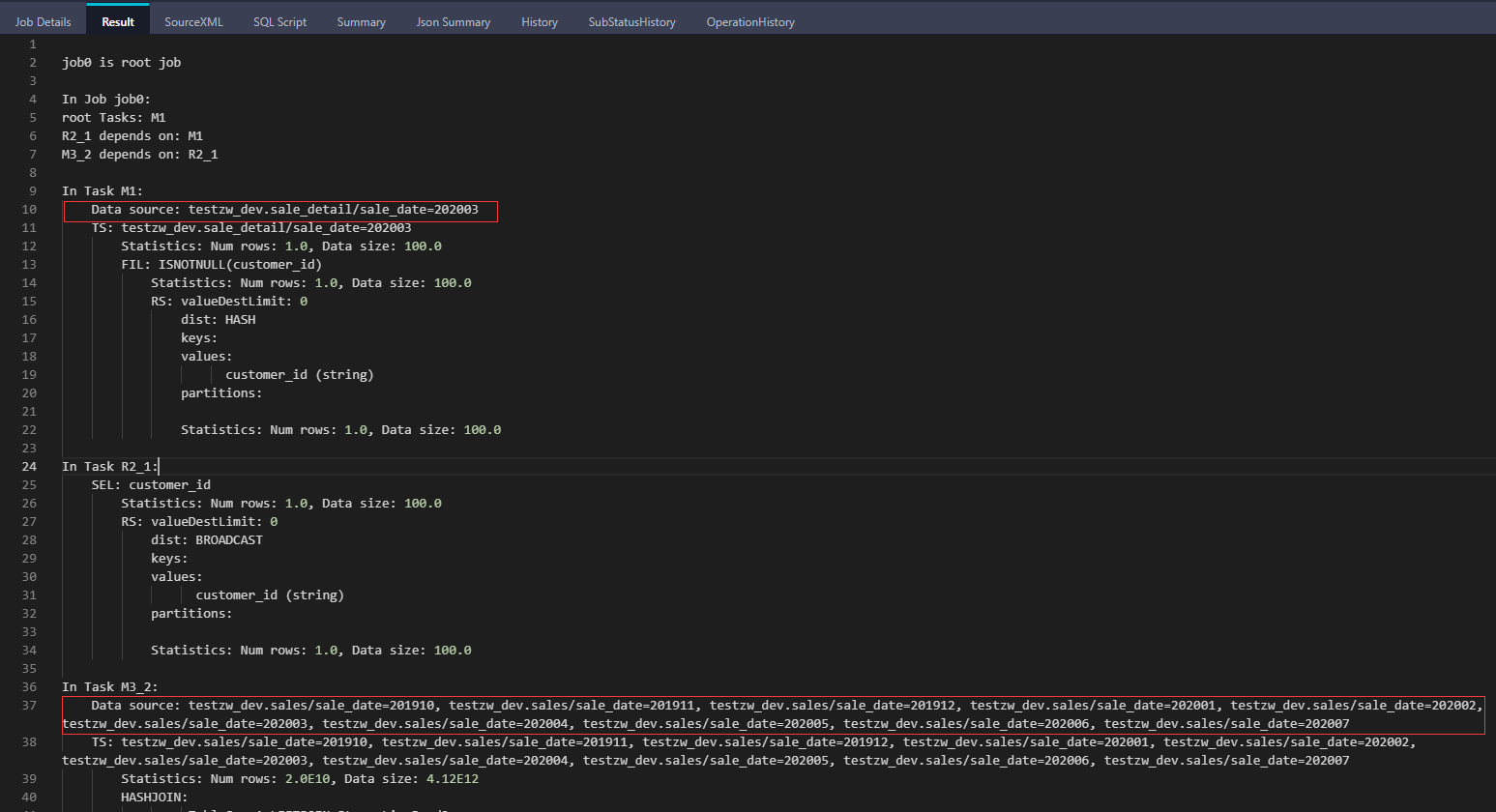
从执行计划中可见,左表(sales)进行了全表扫描,只有右表(sale_detail)的分区裁剪有效果。
- 分区裁剪条件均放在 WHERE 子句中
set odps.sql.allow.fullscan=true; explain select a.customer_id, a.shop_name from sales a left outer join sale_detail b on a.customer_id = b.customer_id where a.sale_date = '202003' and b.sale_date = '202003';
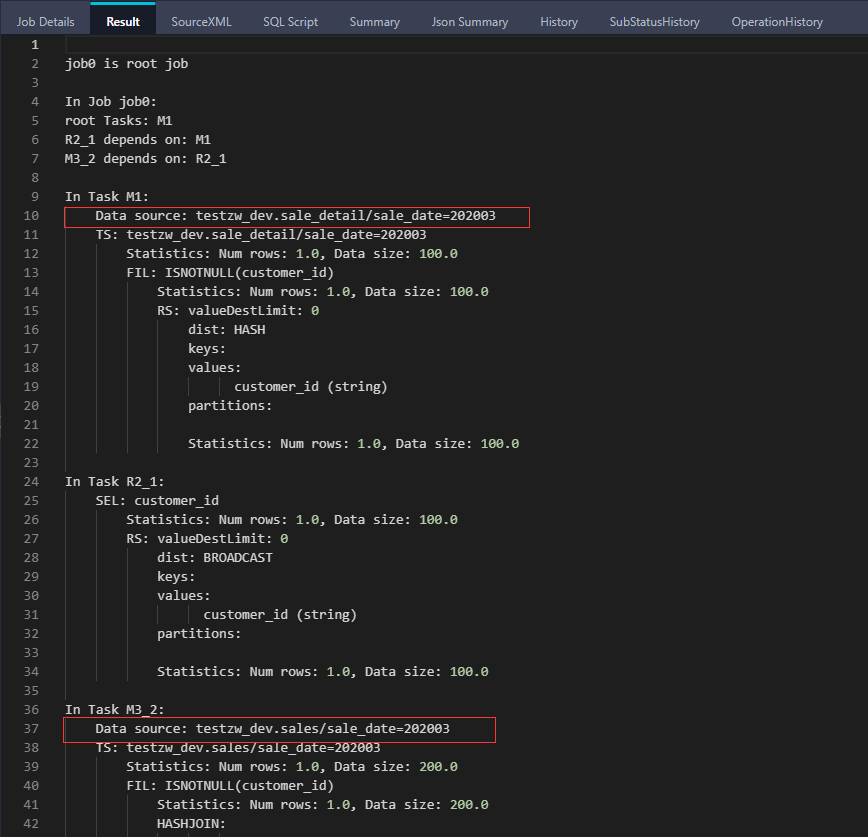
从执行计划中可见,两张表的分区裁剪都有效果。
c. RIGHT OUTER JOIN
与 LEFT OUTER JOIN 类似,如果分区裁剪条件放在 ON 子句中则只有 RIGHT OUTER JOIN 的左表生效。如果分区裁剪条件放在 WHERE 中,则两张表都会生效。
d. FULL OUTER JOIN
分区剪裁条件只有都放在 WHERE 子句中才会生效,放在 ON 子句中都不会生效。
参考资料
原创文章,转载请注明出处:http://www.opcoder.cn/article/62/