最近开始学习大数据相关的知识,最著名的就是开源的 Hadoop 平台了。这里记录一下目前最新版的 Hadoop 在 Ubuntu 系统下的搭建过程。
前提条件
在开始安装 Hadoop 之前,我们需要使用可用的最新软件补丁更新 Ubuntu。
sudo apt-get update && sudo apt-get -y dist-upgrade
安装 JDK
下载 JDK
- JDK 下载地址
https://www.jb51.net/softs/551521.html
- 创建软件下载目录
lichaoxiang@ubuntu-vm:~$ mkdir Download
- 上传 JDK 至 Linux 环境
lichaoxiang@ubuntu-vm:~/Download$ ls jdk-linux-x64.tar.gz
安装 JDK
- 创建软件安装目录
lichaoxiang@ubuntu-vm:~$ sudo mkdir /usr/local/opt
- 解压 JDK 至指定目录下
lichaoxiang@ubuntu-vm:~/Download$ sudo tar -zxvf jdk-linux-x64.tar.gz -C /usr/local/opt/
配置 JDK
- 编辑 /etc/profile 文件,配置环境变量
lichaoxiang@ubuntu-vm:~$ sudo vim /etc/profile
在末尾处添加以下命令:
export JAVA_HOME=/usr/local/opt/jdk1.8.0_131 export CLASSPATH=.:$JAVA_HOME/lib export PATH=$PATH:$JAVA_HOME/bin
- 使环境变量生效
lichaoxiang@ubuntu-vm:~$ source /etc/profile
- 检查是否安装成功
lichaoxiang@ubuntu-vm:~$ java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
- 查看 Linux 的版本
lichaoxiang@ubuntu-vm:~$ more /etc/os-release NAME="Ubuntu" VERSION="21.04 (Hirsute Hippo)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 21.04" VERSION_ID="21.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=hirsute UBUNTU_CODENAME=hirsute
安装 MySQL
- 查看是否已安装 MySQL
dpkg -l | grep mysql
- 安装 MySQL
注:通过 APT 方式安装的版本都是现在最新的版本,通过这种方式安装好之后开机自启动都已经配置好,且命令行上的环境变量无需手动配置。
sudo apt-get install mysql-server
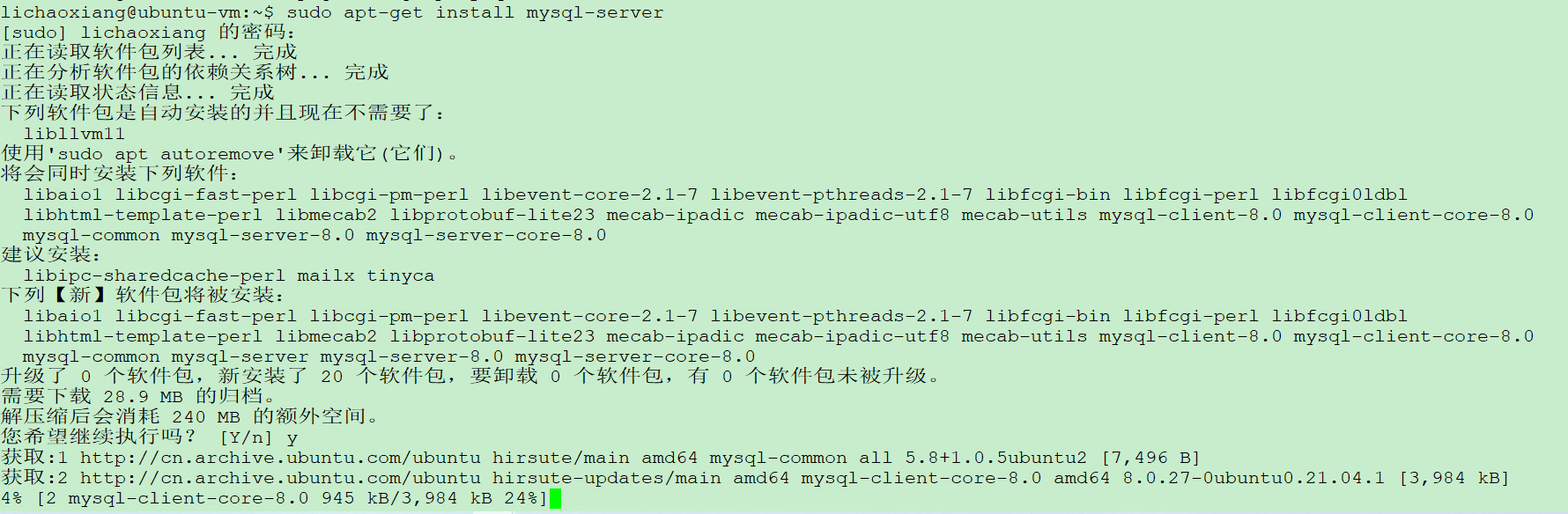
如果提示依赖不足,运行下面命令解决依赖问题,如果没出现依赖问题,那么就不需要使用此命令。
sudo apt-get install -f
- 检查是否安装成功
netstat -tap | grep mysql
通过上述命令检查之后,如果看到有 MySQL 的 socket 处于 LISTEN 状态则表示安装成功。
lichaoxiang@ubuntu-vm:~$ sudo netstat -tap | grep mysql tcp 0 0 localhost:33060 0.0.0.0:* LISTEN 46392/mysqld tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN 46392/mysqld
- 查看已安装的 MySQL 版本
lichaoxiang@ubuntu-vm:~$ mysql -V mysql Ver 8.0.27-0ubuntu0.21.04.1 for Linux on x86_64 ((Ubuntu))
- 检查 MySQL 服务状态
lichaoxiang@ubuntu-vm:~$ service mysql status ● mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2021-11-08 16:43:58 CST; 19min ago Process: 46384 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=exited, status=0/SUCCESS) Main PID: 46392 (mysqld) Status: "Server is operational" Tasks: 38 (limit: 4596) Memory: 354.5M CGroup: /system.slice/mysql.service └─46392 /usr/sbin/mysqld 11月 08 16:43:58 ubuntu-vm systemd[1]: Starting MySQL Community Server... 11月 08 16:43:58 ubuntu-vm systemd[1]: Started MySQL Community Server.
- 查看 root 的默认密码
lichaoxiang@ubuntu-vm:~$ sudo cat /etc/mysql/debian.cnf # Automatically generated for Debian scripts. DO NOT TOUCH! [client] host = localhost user = debian-sys-maint password = nygkYwDcGppIO6qc socket = /var/run/mysqld/mysqld.sock [mysql_upgrade] host = localhost user = debian-sys-maint password = nygkYwDcGppIO6qc socket = /var/run/mysqld/mysqld.sock
- 使用默认 root 密码登录 MySQL
lichaoxiang@ubuntu-vm:~$ sudo mysql -u root -pnygkYwDcGppIO6qc mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 13 Server version: 8.0.27-0ubuntu0.21.04.1 (Ubuntu) Copyright (c) 2000, 2021, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
- 修改 root 密码
mysql> use mysql Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> alter user 'root'@'localhost' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.01 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
- 创建 MySQL 新用户 hive 并授权
mysql> create user 'hive'@'localhost' identified by 'hive'; Query OK, 0 rows affected (0.01 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> grant all privileges on *.* to 'hive'@'localhost' with grant option; Query OK, 0 rows affected (0.01 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
- 退出 root 用户, 使用 hive 用户登陆 MySQL 并创建数据库
lichaoxiang@ubuntu-vm:~$ mysql -uhive -phive mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 8.0.27-0ubuntu0.21.04.1 (Ubuntu) Copyright (c) 2000, 2021, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> create database hive_test; Query OK, 1 row affected (0.01 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | hive_test | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec)
- MySQL 服务相关
# 服务状态 service mysql status # 启动服务 sudo systemctl mysql start # 重启服务 sudo service mysql restart # 关闭服务 sudo service mysql stop
配置 SSH 免密登录
- 安装 ssh-server
sudo apt install openssh-server
- 检查 ssh 是否安装成功
lichaoxiang@ubuntu-vm:~$ ssh localhost lichaoxiang@localhost's password: Welcome to Ubuntu 21.04 (GNU/Linux 5.11.0-38-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage 0 updates can be applied immediately. New release '21.10' available. Run 'do-release-upgrade' to upgrade to it. *** System restart required *** Last login: Mon Nov 8 18:01:35 2021 from 127.0.0.1
安装成功则会提示需要使用密码,输入密码后则会提示连接成功。
- 退出 ssh 连接
lichaoxiang@ubuntu-vm:~$ logout Connection to localhost closed.
- 配置 ssh 免密登陆(生成文件 authorized_keys)
在进行了初次登陆后,会在当前 HOME 目录用户下有一个 .ssh 文件夹,进入该文件夹下。
lichaoxiang@ubuntu-vm:~$ cd ~/.ssh lichaoxiang@ubuntu-vm:~/.ssh$ pwd /home/lichaoxiang/.ssh
- 使用 rsa 算法生成秘钥和公钥对
lichaoxiang@ubuntu-vm:~/.ssh$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/lichaoxiang/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/lichaoxiang/.ssh/id_rsa Your public key has been saved in /home/lichaoxiang/.ssh/id_rsa.pub The key fingerprint is: SHA256:FVRq4ghF+qLznEY4moNn2gAc3Y0g6tcJttJV1uqB2kc lichaoxiang@ubuntu-vm The key's randomart image is: +---[RSA 3072]----+ | . . .oo..o.. | |. o oo= . o | |.. +o+..o + | |o + =+.E + | |.+ =+o= S | |. =o.o o | |oooo . | |=oo+.. | |.=..+ | +----[SHA256]-----+
运行后一路回车就可以了,其中第一个是要输入秘钥和公钥对的保存位置,默认是在 ~/.ssh/id_rsa 下。
- 导入 authorized_keys(把公钥加入到授权中)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 测试是否免密码登录 localhost
lichaoxiang@ubuntu-vm:~$ ssh localhost Welcome to Ubuntu 21.04 (GNU/Linux 5.11.0-38-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage 0 updates can be applied immediately. New release '21.10' available. Run 'do-release-upgrade' to upgrade to it. *** System restart required *** Last login: Mon Nov 8 18:03:50 2021 from 127.0.0.1
再次 ssh localhost 的时候就可以免密登陆了。
安装 Hadoop
下载 Hadoop
- Hadoop 下载地址
https://www.apache.org/dyn/closer.cgi/hadoop/common
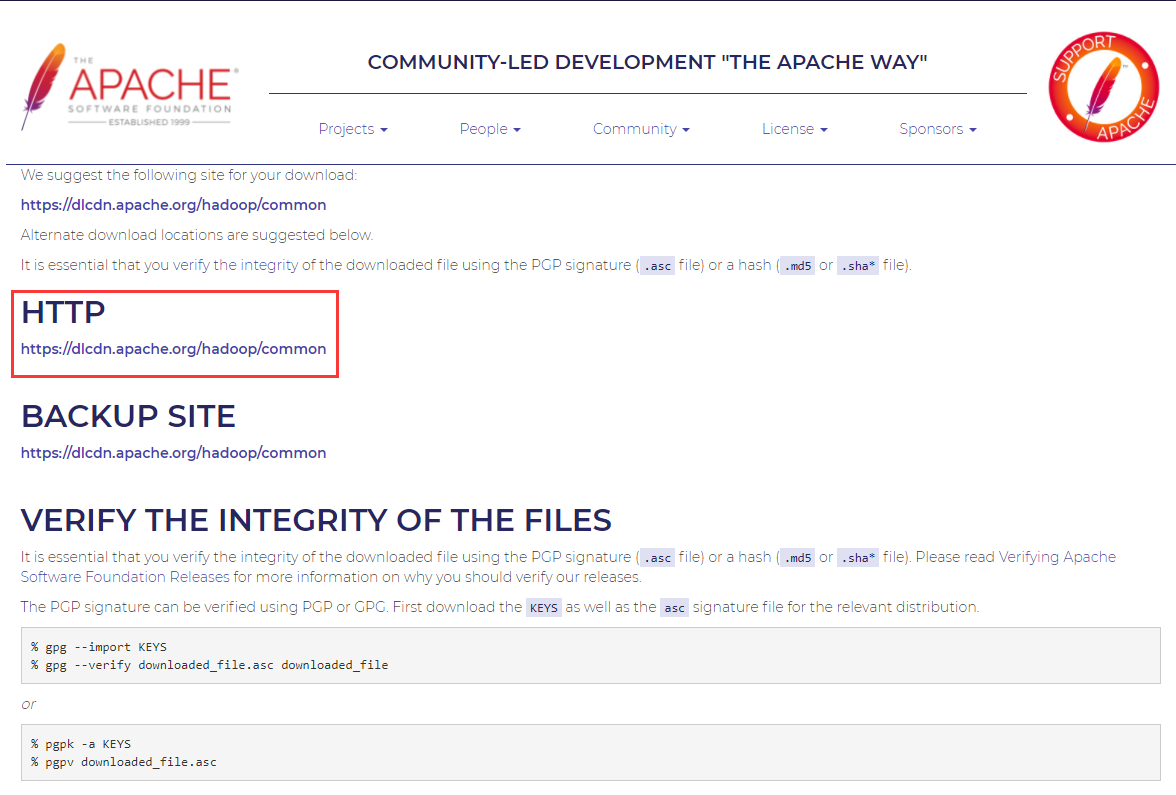
- 上传 Hadoop 至 Linux 环境
lichaoxiang@ubuntu-vm:~/Download$ ls hadoop-3.3.1.tar.gz jdk-17_linux-x64_bin.tar.gz
- 解压 Hadoop 至指定目录下
lichaoxiang@ubuntu-vm:~/Download$ sudo tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local/opt/
- 更新 Hadoop 环境变量配置
lichaoxiang@ubuntu-vm:/usr/local/opt$ sudo vim /etc/profile export HADOOP_HOME=/usr/local/opt/hadoop-3.3.1 export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1$ source /etc/profile
- 检查环境变量
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1$ echo $HADOOP_HOME /usr/local/opt/hadoop-3.3.1
伪分布式模式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中。
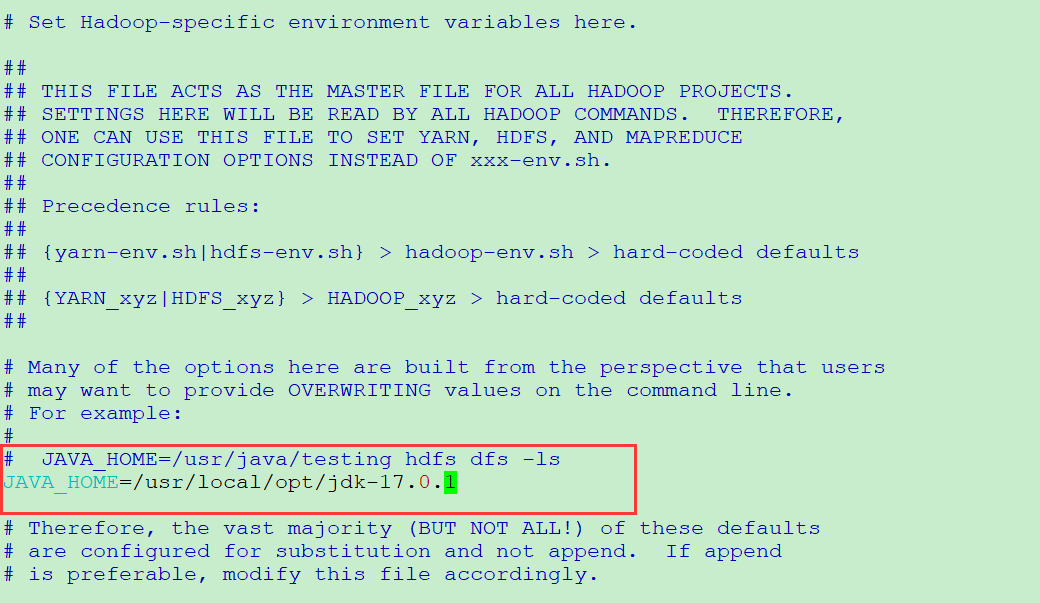
- 配置 hadoop-env.sh
# 修改 java 路径 lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ sudo vim hadoop-env.sh JAVA_HOME=${JAVA_HOME} 改成 JAVA_HOME=JAVA_HOME=/usr/local/opt/jdk1.8.0_131
- 配置 core-site.xml
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ sudo vim core-site.xml <configuration> <!--指定fs的缺省名称--> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <!--指定HDFS的(NameNode)的缺省路径地址,localhost:是计算机名,也可以是ip地址--> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录(以个人为准) --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/opt/hadoop-3.3.1/tmp</value> </property> </configuration>
注:如果没有目录 /usr/local/opt/hadoop-3.3.1/tmp,则需要自己新建该目录。
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ ll /usr/local/opt/hadoop-3.3.1/ 总用量 120 drwxr-xr-x 10 lichaoxiang lichaoxiang 4096 6月 15 13:52 ./ drwxr-xr-x 4 root root 4096 11月 9 09:18 ../ drwxr-xr-x 2 lichaoxiang lichaoxiang 4096 6月 15 13:52 bin/ drwxr-xr-x 3 lichaoxiang lichaoxiang 4096 6月 15 13:15 etc/ drwxr-xr-x 2 lichaoxiang lichaoxiang 4096 6月 15 13:52 include/ drwxr-xr-x 3 lichaoxiang lichaoxiang 4096 6月 15 13:52 lib/ drwxr-xr-x 4 lichaoxiang lichaoxiang 4096 6月 15 13:52 libexec/ -rw-rw-r-- 1 lichaoxiang lichaoxiang 23450 6月 15 13:02 LICENSE-binary drwxr-xr-x 2 lichaoxiang lichaoxiang 4096 6月 15 13:52 licenses-binary/ -rw-rw-r-- 1 lichaoxiang lichaoxiang 15217 6月 15 13:02 LICENSE.txt -rw-rw-r-- 1 lichaoxiang lichaoxiang 29473 6月 15 13:02 NOTICE-binary -rw-rw-r-- 1 lichaoxiang lichaoxiang 1541 5月 22 00:11 NOTICE.txt -rw-rw-r-- 1 lichaoxiang lichaoxiang 175 5月 22 00:11 README.txt drwxr-xr-x 3 lichaoxiang lichaoxiang 4096 6月 15 13:15 sbin/ drwxr-xr-x 4 lichaoxiang lichaoxiang 4096 6月 15 14:18 share/ lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ mkdir /usr/local/opt/hadoop-3.3.1/tmp
- 配置 hdfs-site.xml
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ sudo vim hdfs-site.xml <configuration> <!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/local/opt/hadoop-3.3.1/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/opt/hadoop-3.3.1/hdfs/data</value> </property> </configuration>
注:如果没有目录 /usr/local/opt/hadoop-3.3.1/hdfs/name 和 /usr/local/opt/hadoop-3.3.1/hdfs/data,则需要自己新建该目录。
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ mkdir -p /usr/local/opt/hadoop-3.3.1/hdfs/name lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ mkdir -p /usr/local/opt/hadoop-3.3.1/hdfs/data
- 配置 mapred-site.xml
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ sudo vim mapred-site.xml <configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
- 配置 yarn-site.xml
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ sudo vim yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- 指定ResourceManager的地址 --> <property> <name>yarn.resourcemanage.hostname</name> <value>localhost</value> </property> <!-- 指定reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.application.classpath</name> <value>/usr/local/opt/hadoop-3.3.1/etc/hadoop:/usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/common/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/mapreduce/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn/*</value> </property> </configuration>
其中 yarn.application.classpath 的 value 内容通过以下方式获取, 直接复制即可。
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1$ hadoop classpath /usr/local/opt/hadoop-3.3.1/etc/hadoop:/usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/common/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/hdfs/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/mapreduce/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn/lib/*:/usr/local/opt/hadoop-3.3.1/share/hadoop/yarn/*
启动 Hadoop
- 格式化 namenode
对 HDFS 集群进行格式化,HDFS 集群是用来存储数据的。
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ hdfs namenode -format WARNING: /usr/local/opt/hadoop-3.3.1/logs does not exist. Creating. 2021-11-09 10:53:03,906 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = ubuntu-vm/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.3.1
- 启动 hadoop hdfs
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ start-all.sh WARNING: Attempting to start all Apache Hadoop daemons as lichaoxiang in 10 seconds. WARNING: This is not a recommended production deployment configuration. WARNING: Use CTRL-C to abort. Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [ubuntu-vm] Starting resourcemanager Starting nodemanagers
- 通过 jps 查看启动的 hadoop 服务
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ jps 4082 Jps 3603 SecondaryNameNode 3214 NameNode 3359 DataNode
- 执行计算任务
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
2021-11-09 12:52:12,134 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2021-11-09 12:52:12,613 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/lichaoxiang/.staging/job_1636433506029_0001
2021-11-09 12:52:13,167 INFO input.FileInputFormat: Total input files to process : 10
2021-11-09 12:52:13,640 INFO mapreduce.JobSubmitter: number of splits:10
2021-11-09 12:52:13,830 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1636433506029_0001
2021-11-09 12:52:13,831 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-11-09 12:52:14,031 INFO conf.Configuration: resource-types.xml not found
2021-11-09 12:52:14,032 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-11-09 12:52:14,367 INFO impl.YarnClientImpl: Submitted application application_1636433506029_0001
2021-11-09 12:52:14,420 INFO mapreduce.Job: The url to track the job: http://ubuntu-vm:8088/proxy/application_1636433506029_0001/
2021-11-09 12:52:14,421 INFO mapreduce.Job: Running job: job_1636433506029_0001
2021-11-09 12:52:23,575 INFO mapreduce.Job: Job job_1636433506029_0001 running in uber mode : false
2021-11-09 12:52:23,577 INFO mapreduce.Job: map 0% reduce 0%
2021-11-09 12:52:45,409 INFO mapreduce.Job: map 60% reduce 0%
2021-11-09 12:52:58,527 INFO mapreduce.Job: map 100% reduce 0%
2021-11-09 12:53:00,549 INFO mapreduce.Job: map 100% reduce 100%
2021-11-09 12:53:00,563 INFO mapreduce.Job: Job job_1636433506029_0001 completed successfully
2021-11-09 12:53:00,698 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=3009266
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2690
HDFS: Number of bytes written=215
HDFS: Number of read operations=45
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=165307
Total time spent by all reduces in occupied slots (ms)=11850
Total time spent by all map tasks (ms)=165307
Total time spent by all reduce tasks (ms)=11850
Total vcore-milliseconds taken by all map tasks=165307
Total vcore-milliseconds taken by all reduce tasks=11850
Total megabyte-milliseconds taken by all map tasks=169274368
Total megabyte-milliseconds taken by all reduce tasks=12134400
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1510
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=4139
CPU time spent (ms)=10010
Physical memory (bytes) snapshot=3187793920
Virtual memory (bytes) snapshot=37711335424
Total committed heap usage (bytes)=2828533760
Peak Map Physical memory (bytes)=329674752
Peak Map Virtual memory (bytes)=3427729408
Peak Reduce Physical memory (bytes)=209952768
Peak Reduce Virtual memory (bytes)=3436142592
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 48.652 seconds
Estimated value of Pi is 3.20000000000000000000
- 打开 hadoop 集群 Web 页面
http://localhost:9870/
停止 Hadoop
lichaoxiang@ubuntu-vm:/usr/local/opt/hadoop-3.3.1/etc/hadoop$ stop-all.sh
安装 Hive
下载 Hive
- Hadoop 下载地址
http://www.apache.org/dyn/closer.cgi/hive/
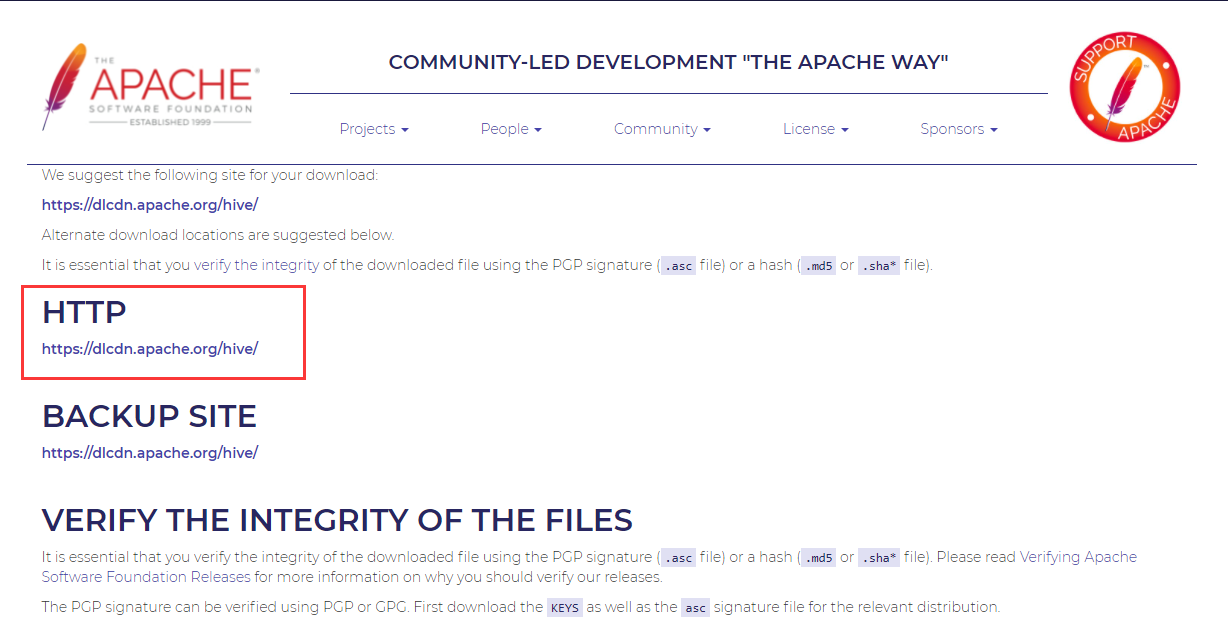
- 上传 Hive 至 Linux 环境
lichaoxiang@ubuntu-vm:~/Download$ ls apache-hive-3.1.2-bin.tar.gz
- 解压 Hive 至指定目录下
lichaoxiang@ubuntu-vm:~/Download$ sudo tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/opt/
安装 Hive
- 编辑 /etc/profile 文件,配置 Hive 环境变量
lichaoxiang@ubuntu-vm:~$ sudo vim /etc/profile
在末尾处添加以下命令:
export HIVE_HOME=/usr/local/opt/apache-hive-3.1.2-bin export PATH=${PATH}:${HIVE_HOME}/bin
- 使环境变量生效
lichaoxiang@ubuntu-vm:~$ source /etc/profile
- 配置 Hive
lichaoxiang@ubuntu-vm:~$ cd /usr/local/opt/apache-hive-3.1.2-bin/conf/ lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo cp ./hive-default.xml.template ./hive-default.xml lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo cp ./hive-env.sh.template ./hive-env.sh lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo cp ./hive-log4j2.properties.template ./hive-log4j2.properties lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo touch ./hive-site.xml
- 修改 hive-env.sh 文件
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo vim ./hive-env.sh export HADOOP_HOME=/usr/local/opt/hadoop-3.3.1 export HIVE_CONF_DIR=/usr/local/opt/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/usr/local/opt/apache-hive-3.1.2-bin/lib
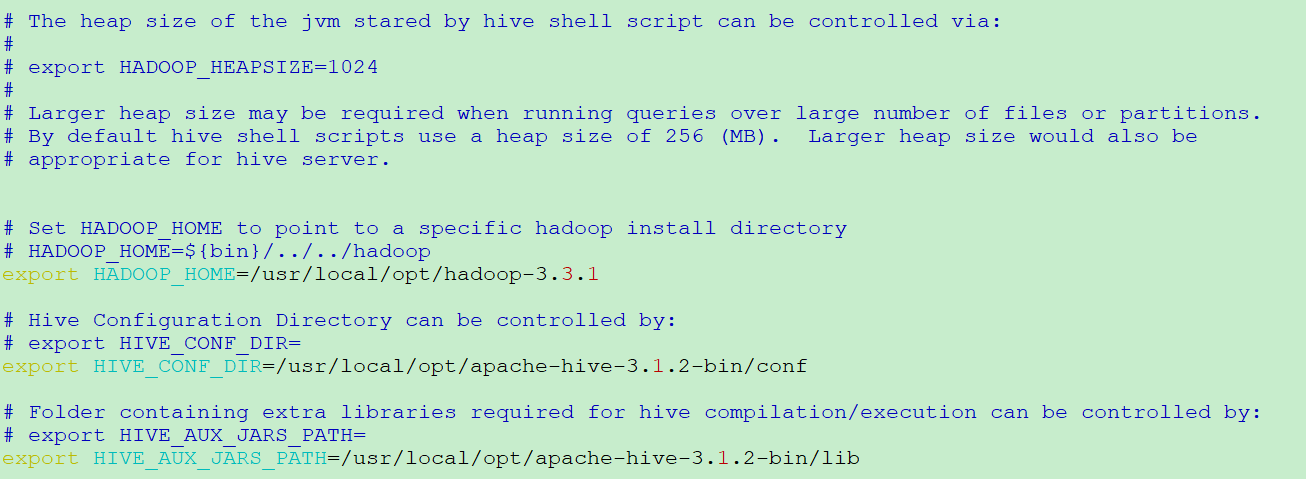
- 修改 hive-log4j2.properties 文件
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo vim ./hive-log4j2.properties property.hive.log.dir = /usr/local/opt/apache-hive-3.1.2-bin/logs/*** appender.DRFA.fileName = /usr/local/opt/apache-hive-3.1.2-bin/logs/${sys:hive.log.file} appender.DRFA.filePattern = /usr/local/opt/apache-hive-3.1.2-bin/logs/${sys:hive.log.file}.%d{yyyy-MM-dd}
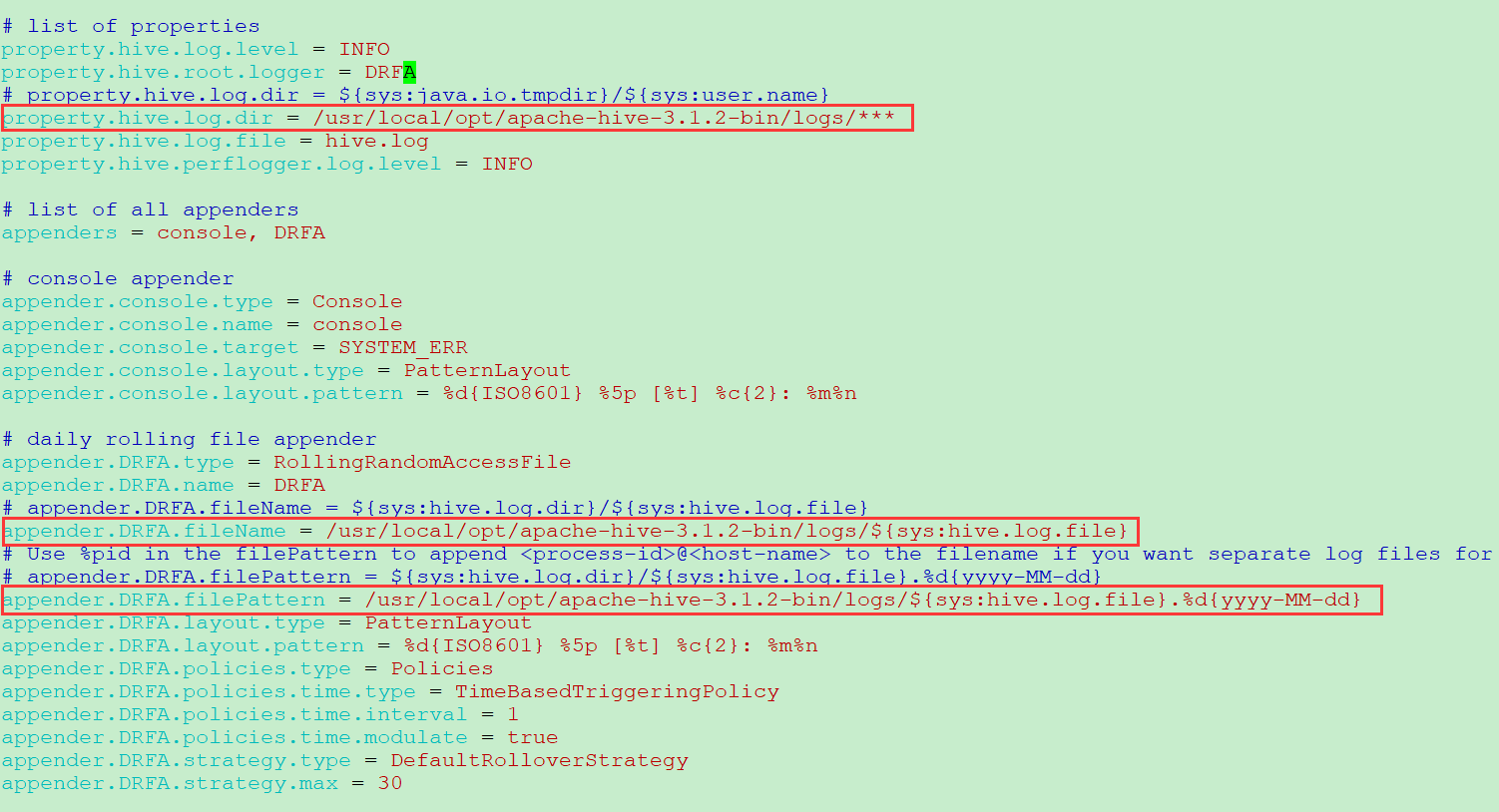
注:如果没有目录 /usr/local/opt/apache-hive-3.1.2-bin/logs,则需要自己新建该目录。
lichaoxiang@ubuntu-vm:~$ sudo mkdir -p /usr/local/opt/apache-hive-3.1.2-bin/logs
- 修改 hive-site.xml 文件
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/conf$ sudo vim hive-site.xml <configuration> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> </configuration>
初次配置可以使用以上 hive-site.xml 内容;熟悉之后可以使用上文提到 hive-default.xml 内容进行配置,同时删除以上 hive-site.xml 并将配置好的 hive-default.xml 重命名为 hive.site.xml。
执行前准备
- hdfs 中创建 hive 配置的文件路径
lichaoxiang@ubuntu-vm:~$ hdfs dfs -mkdir -p /user/hive/warehouse lichaoxiang@ubuntu-vm:~$ hdfs dfs -ls -R / | grep 'hive' drwx-wx-wx - lichaoxiang supergroup 0 2021-11-09 13:05 /tmp/hive drwx------ - lichaoxiang supergroup 0 2021-11-09 13:05 /tmp/hive/lichaoxiang drwxr-xr-x - lichaoxiang supergroup 0 2021-11-09 13:34 /user/hive drwxr-xr-x - lichaoxiang supergroup 0 2021-11-09 13:34 /user/hive/warehouse
- 添加 MySQL 的驱动包到 hive/lib 文件夹下
lichaoxiang@ubuntu-vm:~$ sudo cp Download/mysql-connector-java-8.0.21/mysql-connector-java-8.0.21.jar /usr/local/opt/apache-hive-3.1.2-bin/lib/ lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ ls -al | grep 'mysql' -rw-r--r-- 1 root root 2397321 11月 9 13:53 mysql-connector-java-8.0.21.jar -rw-r--r-- 1 root staff 10476 11月 16 2018 mysql-metadata-storage-0.12.0.jar lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ sudo chmod -R 755 ./mysql-connector-java-8.0.21.jar
下载地址:https://dev.mysql.com/downloads/file/?id=496589
- 替换低版本 guava jar 包
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ ls -al | grep 'guava' -rw-r--r-- 1 root staff 2308517 9月 27 2018 guava-19.0.jar -rw-r--r-- 1 root staff 971309 5月 21 2019 jersey-guava-2.25.1.jar lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ ls -al /usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/*.jar | grep 'guava' -rw-r--r-- 1 lichaoxiang lichaoxiang 2747878 6月 15 13:15 /usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/guava-27.0-jre.jar -rw-r--r-- 1 lichaoxiang lichaoxiang 3362359 6月 15 13:15 /usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/hadoop-shaded-guava-1.1.1.jar -rw-r--r-- 1 lichaoxiang lichaoxiang 2199 6月 15 13:15 /usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ sudo cp /usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/guava-27.0-jre.jar ./ lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ ls -al | grep 'guava' -rw-r--r-- 1 root staff 2308517 9月 27 2018 guava-19.0.jar -rw-r--r-- 1 root root 2747878 11月 9 13:57 guava-27.0-jre.jar -rw-r--r-- 1 root staff 971309 5月 21 2019 jersey-guava-2.25.1.jar
- 初始化 hiveSchema
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ cd lichaoxiang@ubuntu-vm:~$ sudo /usr/local/opt/apache-hive-3.1.2-bin/bin/schematool -dbType mysql -initSchema SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/opt/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/opt/hadoop-3.3.1/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true Metastore Connection Driver : com.mysql.cj.jdbc.Driver Metastore connection User: hive Starting metastore schema initialization to 3.1.0 Initialization script hive-schema-3.1.0.mysql.sql
- 删除 hive 的 log4j-slf4j-impl.jar 包
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ ls -al | grep 'log4j-slf4j-impl' -rw-r--r-- 1 root staff 24173 9月 27 2018 log4j-slf4j-impl-2.10.0.jar lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/lib$ sudo mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar-bak
执行 Hive
执行 Hive 前需要使用(start-all.sh)启动 Hadoop 伪分布模式环境。
lichaoxiang@ubuntu-vm:~$ hive Logging initialized using configuration in file:/usr/local/opt/apache-hive-3.1.2-bin/conf/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Hive Session ID = 931026ae-acd8-4d70-be83-3ef397c45a8e
- 创建 hive 库表并插入数据
hive> create database hive; OK Time taken: 0.198 seconds hive> use hive; OK Time taken: 0.033 seconds
启动 hiveserver2
- 修改 core-site.xml 文件,添加如下内容
lichaoxiang@ubuntu-vm:~$ sudo vim /usr/local/opt/hadoop-3.3.1/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.lichaoxiang.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.lichaoxiang.groups</name>
<value>*</value>
</property>
- 修改 hive-site.xml 文件,添加如下内容
lichaoxiang@ubuntu-vm:~$ sudo vim /usr/local/opt/apache-hive-3.1.2-bin/conf/hive-site.xml
<property>
<name>beeline.hs2.connection.user</name>
<value>hive</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>hive</value>
</property>
<property>
<name>beeline.hs2.connection.hosts</name>
<value>localhost:10000</value>
</property>
- 重启 Hadoop
lichaoxiang@ubuntu-vm:~$ stop-all.sh lichaoxiang@ubuntu-vm:~$ start-all.sh
- 进入 hive 的 bin 目录,启动 hiveserver2
lichaoxiang@ubuntu-vm:~$ cd /usr/local/opt/apache-hive-3.1.2-bin/bin lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/bin$ hiveserver2 2021-11-09 17:26:01: Starting HiveServer2 . . . Hive Session ID = d9d6f67a-cb2b-4007-b074-a3c8ef046cc1 Hive Session ID = 3aa9ef99-315a-4a1a-82b0-c965aacca06b Hive Session ID = 55b2814f-68ec-478e-919d-944efaaff474 Hive Session ID = 8bdaf869-7ab1-4d7f-b3e2-9d1bddde47b5 OK
- 另起一个窗口
lichaoxiang@ubuntu-vm:~$ beeline Beeline version 3.1.2 by Apache Hive beeline> !connect jdbc:hive2://localhost:10000 Connecting to jdbc:hive2://localhost:10000 Enter username for jdbc:hive2://localhost:10000: lichaoxiang Enter password for jdbc:hive2://localhost:10000: ******** Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000>
配置 DBeaver
- 下载 DBeaver
链接: https://pan.baidu.com/s/1nSmsiFd-KCi5-gCYsO-uWA
提取码: e92x
- 新建连接
- 选择新连接类型
- 编辑驱动设置
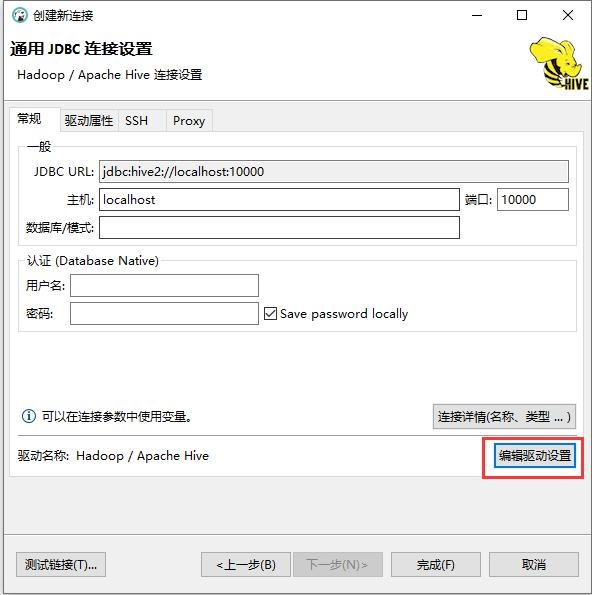
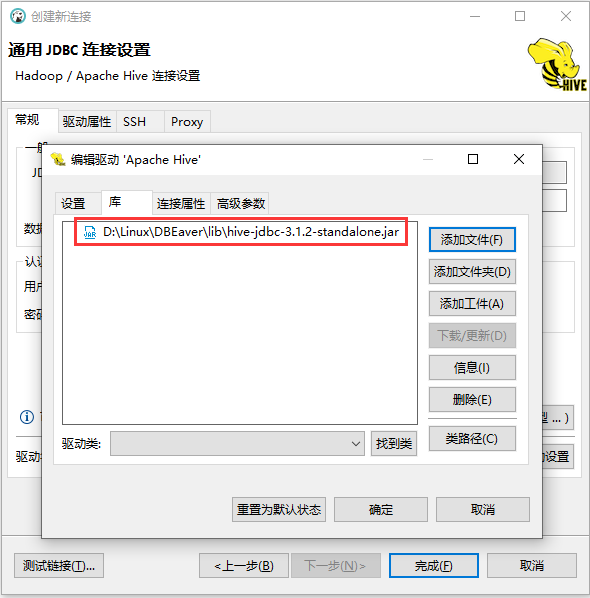
- 使用 hive 自带的 jdbc jar
lichaoxiang@ubuntu-vm:/usr/local/opt/apache-hive-3.1.2-bin/jdbc$ ls hive-jdbc-3.1.2-standalone.jar
然后将 DBeaver 默认的 jar 删除,再添加上 hive 自带的 jdbc jar 包。
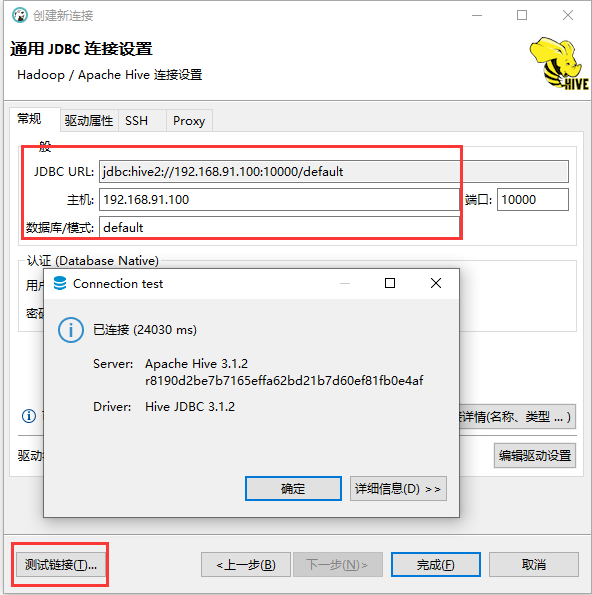
- 配置连接
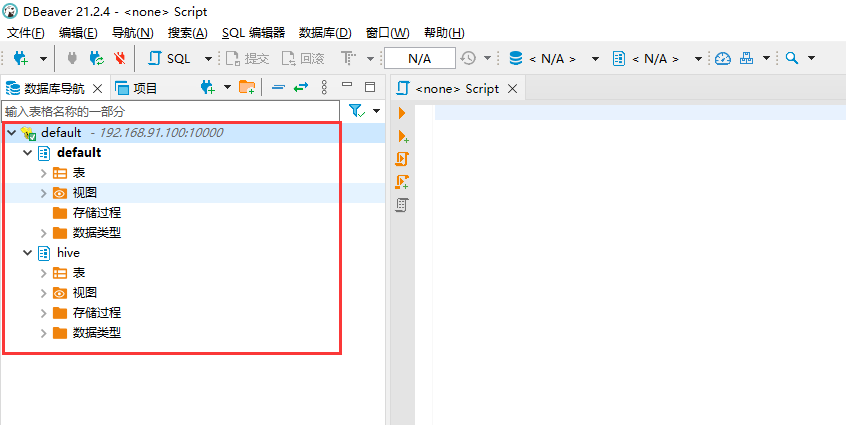
异常处理
- Browse Directory 报错
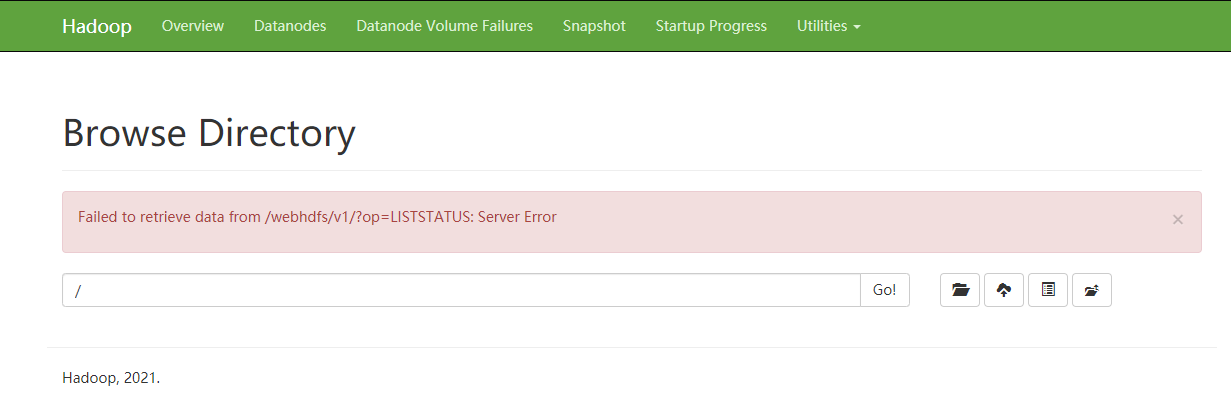
解决办法:该问题时由于Java版本导致的,本地安装了多个版本,默认使用版本 Java16,版本过高。修改 Java 版本到 1.8,问题就能解决。
换成 1.8 版本后,页面显示结果如下:
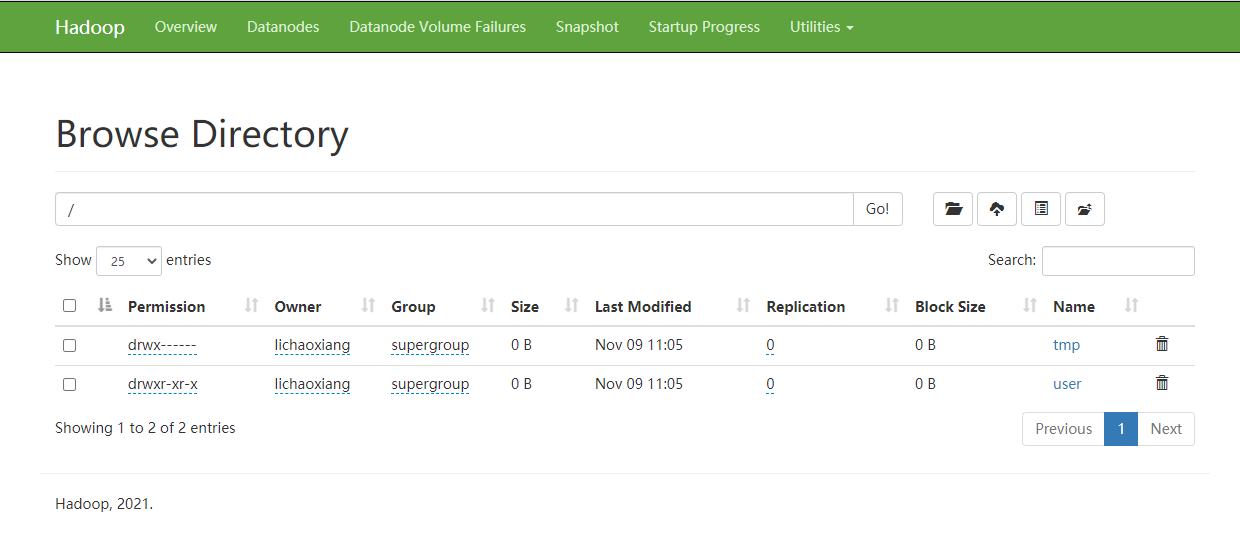
- 执行计算任务时报错,/bin/bash: 行 1: /bin/java: 没有那个文件或目录
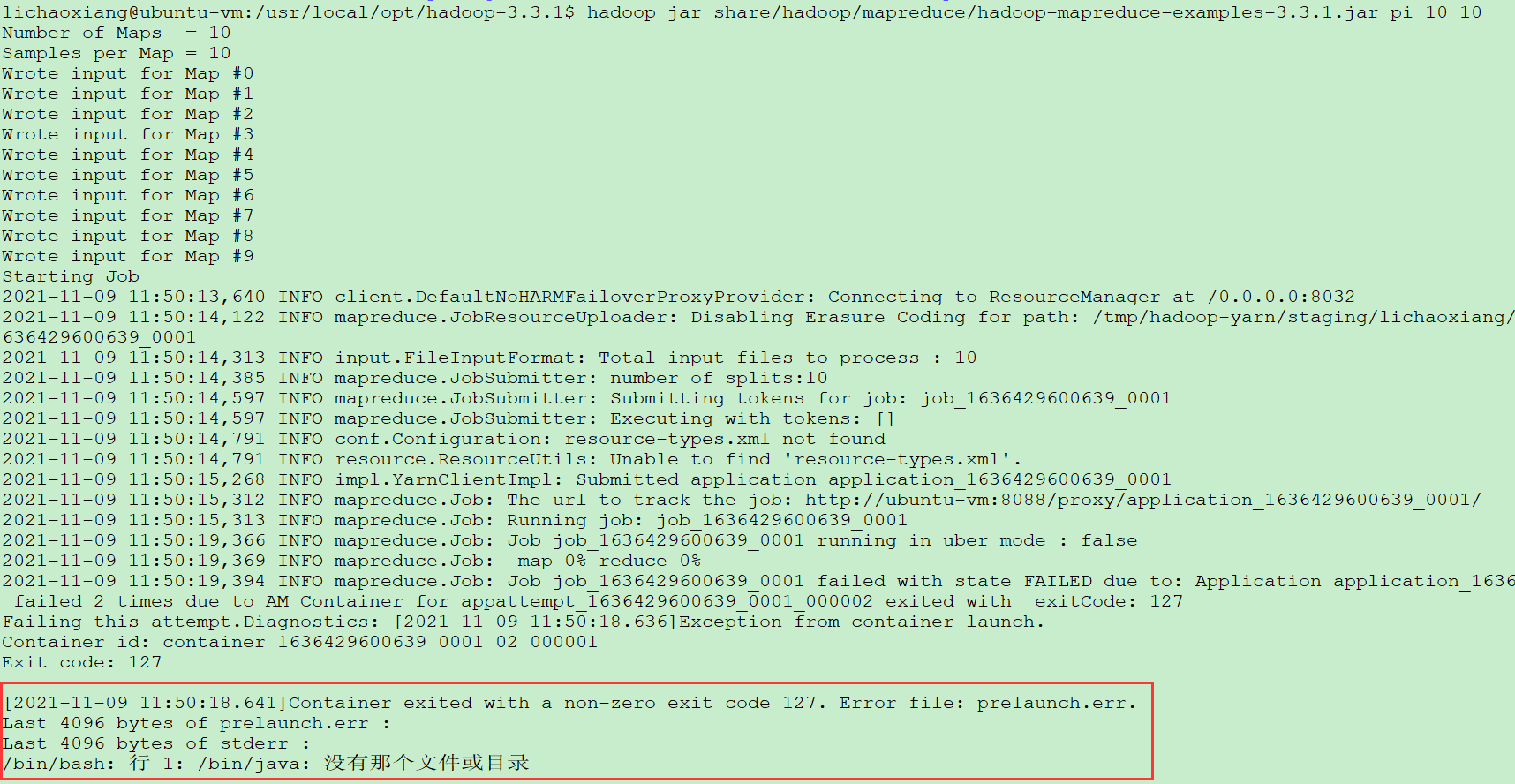
解决办法:创建软链接
lichaoxiang@ubuntu-vm:/usr/local/opt/jdk1.8.0_131/bin$ sudo ln -s /usr/local/opt/jdk1.8.0_131/bin/java /bin/java
参考资料
Ubuntu 20.04.1 LTS 安装 Hadoop3.3.0 和 Hive3.1.2
Hadoop 安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
原创文章,转载请注明出处:http://www.opcoder.cn/article/48/