在 Oracle 数据库中,执行计划是 SQL 优化最为复杂也是最为关键的一部分,因为它实际上 代表了目标 SQL 在 Oracle 数据库内部的具体执行步骤,只有知道并理解了这些执行步骤,我们才能知道优化器选择的执行计划是否为当前情形下最优的执行计划,也才能知道是否需要对当前的执行计划做出调整。
权限
SQL> grant dba to scott; SQL> grant select on v_$session to scott;
数据准备
SQL> conn scott/tiger@localhost/orcl Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as scott@localhost/orcl SQL> create table t1 as select * from dba_objects; Table created SQL> create table t2 as select * from dba_objects; Table created
什么是执行计划
为了执行 SQL 语句,Oracle 在内部必须实现许多步骤,这些步骤可能是从数据库中物理检索数据行,或者用某种方法来准备数据行等,接着 Oracle 会按照一定的顺序依次执行这些步骤,最后将其执行结果作为目标 SQL 的最终执行结果返回给用户。Oracle 用来执行目标 SQL 语句的这些步骤的组合就称为执行计划。
执行计划的结构
执行下述目标 SQL 后,使用 DBMS_XPLAN 包中的方法 DISPLAY_CURSOR 查看其执行计划。
SQL> set serveroutput off; SQL> alter session set statistics_level = all; 会话已更改。 SQL> select t1.owner, t1.object_id, t1.object_name, t1.object_type from t1, t2 where t1.object_id = t2.object_id and t1.owner = 'SCOTT'; OWNER OBJECT_ID OBJECT_NAME OBJECT_TYPE ---------- ---------- ------------------------------ ------------------- SCOTT 86892 PK_DEPT INDEX SCOTT 86891 DEPT TABLE SCOTT 86893 EMP TABLE SCOTT 86895 BONUS TABLE SCOTT 86896 SALGRADE TABLE SCOTT 87186 PK_EMP_BAK INDEX SCOTT 87185 EMP_BAK TABLE SCOTT 87187 DEPT_BAK TABLE SCOTT 87188 PK_DEPT_BAK INDEX SCOTT 87224 DDL_EVENT TABLE SCOTT 87265 DEPT_SUMMARY TABLE SCOTT 87225 TRI_DDL TRIGGER SCOTT 87226 INS_EMP TABLE SCOTT 87229 TRI_LOGON TRIGGER SCOTT 87228 LOGON_EVENT TABLE SCOTT 87494 PKG_REFCURSOR_OPEN_DEMO PACKAGE BODY SCOTT 87489 P_EMP_SETS PROCEDURE SCOTT 87493 PKG_REFCURSOR_OPEN_DEMO PACKAGE SCOTT 87516 T1 TABLE 已选择19行。 SQL> select * from table(dbms_xplan.display_cursor(null, null, 'advanced allstats last')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SQL_ID da1ud26t4dw5b, child number 0 ------------------------------------- select t1.owner, t1.object_id, t1.object_name, t1.object_type from t1, t2 where t1.object_id = t2.object_id and t1.owner = 'SCOTT' Plan hash value: 1838229974 ------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 686 (100)| | 19 |00:00:00.03 | 2472 | | | | |* 1 | HASH JOIN | | 1 | 14 | 1680 | 686 (1)| 00:00:09 | 19 |00:00:00.03 | 2472 | 1172K| 1172K| 1247K (0)| |* 2 | TABLE ACCESS FULL| T1 | 1 | 14 | 1498 | 343 (1)| 00:00:05 | 19 |00:00:00.01 | 1235 | | | | | 3 | TABLE ACCESS FULL| T2 | 1 | 93392 | 1185K| 343 (1)| 00:00:05 | 86124 |00:00:00.01 | 1237 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- 1 - SEL$1 2 - SEL$1 / T1@SEL$1 3 - SEL$1 / T2@SEL$1 Outline Data ------------- /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.4') DB_VERSION('11.2.0.4') OPT_PARAM('star_transformation_enabled' 'true') ALL_ROWS OUTLINE_LEAF(@"SEL$1") FULL(@"SEL$1" "T1"@"SEL$1") FULL(@"SEL$1" "T2"@"SEL$1") LEADING(@"SEL$1" "T1"@"SEL$1" "T2"@"SEL$1") USE_HASH(@"SEL$1" "T2"@"SEL$1") END_OUTLINE_DATA */ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID") 2 - filter("T1"."OWNER"='SCOTT') Column Projection Information (identified by operation id): ----------------------------------------------------------- 1 - (#keys=1) "T1"."OBJECT_ID"[NUMBER,22], "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."OBJECT_TYPE"[VARCHAR2,19] 2 - "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."OBJECT_ID"[NUMBER,22], "T1"."OBJECT_TYPE"[VARCHAR2,19] 3 - "T2"."OBJECT_ID"[NUMBER,22] Note ----- - dynamic sampling used for this statement (level=2) 已选择59行。
从显示的结果可以看到,上述目标 SQL 的执行计划可以分为如下三个部分。
- 目标 SQL 的正文、SQL_ID 和其执行计划所对应的 PLAN_HASH_VALUE
SQL_ID da1ud26t4dw5b, child number 0 ------------------------------------- select t1.owner, t1.object_id, t1.object_name, t1.object_type from t1, t2 where t1.object_id = t2.object_id and t1.owner = 'SCOTT' Plan hash value: 1838229974
根据上述执行计划中的内容,可以看到该 SQL 的 SQL_ID 是 da1ud26t4dw5b,SQL 正文是 “select t1.owner, t1.object_id, t1.object_name, t1.object_type from t1, t2 where t1.object_id = t2.object_id and t1.owner = 'SCOTT'”,其执行计划所对应的 Plan Hash Value 是 1838229974。
- 执行计划的主体部分
从其中我们可以看到在执行目标 SQL 时所用的内部执行步骤,这些步骤的执行顺序,所对应的谓词信息、列信息,优化器评估出来执行这些步骤后返回结果集的 Cardinality、成本等内容。
------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 686 (100)| | 19 |00:00:00.03 | 2472 | | | | |* 1 | HASH JOIN | | 1 | 14 | 1680 | 686 (1)| 00:00:09 | 19 |00:00:00.03 | 2472 | 1172K| 1172K| 1247K (0)| |* 2 | TABLE ACCESS FULL| T1 | 1 | 14 | 1498 | 343 (1)| 00:00:05 | 19 |00:00:00.01 | 1235 | | | | | 3 | TABLE ACCESS FULL| T2 | 1 | 93392 | 1185K| 343 (1)| 00:00:05 | 86124 |00:00:00.01 | 1237 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- 1 - SEL$1 2 - SEL$1 / T1@SEL$1 3 - SEL$1 / T2@SEL$1 Outline Data ------------- /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.4') DB_VERSION('11.2.0.4') OPT_PARAM('star_transformation_enabled' 'true') ALL_ROWS OUTLINE_LEAF(@"SEL$1") FULL(@"SEL$1" "T1"@"SEL$1") FULL(@"SEL$1" "T2"@"SEL$1") LEADING(@"SEL$1" "T1"@"SEL$1" "T2"@"SEL$1") USE_HASH(@"SEL$1" "T2"@"SEL$1") END_OUTLINE_DATA */ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID") 2 - filter("T1"."OWNER"='SCOTT') Column Projection Information (identified by operation id): ----------------------------------------------------------- 1 - (#keys=1) "T1"."OBJECT_ID"[NUMBER,22], "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."OBJECT_TYPE"[VARCHAR2,19] 2 - "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."OBJECT_ID"[NUMBER,22], "T1"."OBJECT_TYPE"[VARCHAR2,19] 3 - "T2"."OBJECT_ID"[NUMBER,22]
根据上述执行计划中的内容,可以看到 Oracle 在执行目标 SQL 时使用了对表 T1 和 T2 的哈希连接,CBO 评估出来上述哈希连接返回结果集的 Cardinality 的值是 19(A-Rows),成本值为 686(Cost (%CPU))。执行计划中的 “Query Block Name” 和 “Outline Data” 部分是 CBO 在执行 SQL 时所用到的 Query Block 的名称和用于固定执行计划的内部 Hint 组合。实际上可以将 “Outline Data” 部分的内容摘出来加到目标 SQL 中以固定其执行计划,即可以将目标 SQL 改写成如下的形式:
select /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.4') DB_VERSION('11.2.0.4') OPT_PARAM('star_transformation_enabled' 'true') ALL_ROWS OUTLINE_LEAF(@"SEL$1") FULL(@"SEL$1" "T1"@"SEL$1") FULL(@"SEL$1" "T2"@"SEL$1") LEADING(@"SEL$1" "T1"@"SEL$1" "T2"@"SEL$1") USE_HASH(@"SEL$1" "T2"@"SEL$1") END_OUTLINE_DATA */ t1.owner, t1.object_id, t1.object_name, t1.object_type from t1, t2 where t1.object_id = t2.object_id and t1.owner = 'SCOTT';
注意,在上述执行计划中 Id 为 1 的执行步骤 “HASH JOIN” 前面有一个星号(Id 列的数字 1 前面有一个 “*”),表示该执行步骤有对应的驱动(access)或者过滤查询(filter)条件,这个星号所对应的具体的驱动或过滤查询条件可以从执行计划的 “Predicate Information (identified by operation id)” 中找到。实际上,这部分内容就是上述执行步骤所对应的谓词信息:
Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
从上面的信息可以看到,“access("T1"."OBJECT_ID"="T2"."OBJECT_ID")” 前面的数字也是 1,这里关键字 “access” 表示驱动查询条件,这就表明 "T1"."OBJECT_ID"="T2"."OBJECT_ID" 就是上述执行计划中 Id 为 1 的执行步骤 “HASH JOIN” 所对应的驱动查询条件。
执行计划中 “Column Projection Information (identified by operation id)” 部分的内容就是执行步骤所对应的列信息。
- 执行计划的额外补充信息
从这部分内容中,我们可以看到 Oracle 在执行目标 SQL 时有没有使用一些额外的技术手段,比如是否使用了动态采样及动态采用的级别,是否使用 SQL Profile(Oracle 10g 中引入的调整、稳定执行计划的一种方法)等。
这部分额外的补充信息可以从执行计划中的 “Note” 部分看到,上述完整执行计划中 “Note” 部分的内容如下:
Note ----- - dynamic sampling used for this statement (level=2)
可以看到 Oracle 在执行目标 SQL 时使用了动态采样且采样级别为 2。
当使用 SQL Profile 后,执行计划中 “Note” 部分显示的内容如下:
Note ----- - SQL profile SYS_SQLPROF_01339cce6e980001 used for this statement
什么是真实的执行计划
Oracle 的执行计划分为预估执行计划和真实执行计划。其中,使用 PL/SQL Developer F5、EXPLAIN PLAN FOR 或 SET ATUOTRACE TRACEONLY 等获取的执行计划都是预估的执行计划。
在 Oracle 数据库中判断得到的执行计划是否准确,就是看目标 SQL 是否被真正执行,真正执行过的 SQL 所对应的执行计划就是准确的,反之则有可能不准。
| 序号 | 执行计划分类 | 描述 |
| 1 | PL/SQL Developer F5 | 预估执行计划 |
| 2 | explain plan for | 预估执行计划 |
| 3 | set autotrace traceonly | 预估执行计划 |
| 4 | dbms_xplan.display | 预估执行计划 |
| 5 | set autotrace on | 真实执行计划 |
| 6 | dbms_xplan.display_cusor | 真实执行计划 |
| 7 | dbms_xplan.display_awr | 真实执行计划 |
-
预估执行计划:目标 SQL 并未真正执行,“预估” 的执行计划,并不一定准确,来自
PLAN_TABLE$ -
真实执行计划:目标 SQL 真实执行,“真实” 的执行计划,来自
V$SQL_PLAN
--创建测试表 T1 并插入数据
SQL> create table t1 as select * from dba_objects;
SQL> insert into t1 select * from t1;
SQL> commit;
--在表 T1 的列 OBJECT_ID 上创建一个单键值的 B-tree 索引 IDX_T1
SQL> create index idx_t1 on t1(object_id);
--对表 T1 收集统计信息
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'T1', estimate_percent => 100, cascade => true);
--创建两个绑定变量 x 和 y,分别对它们赋值 0 和 100000
SQL> var x number;
SQL> var y number;
SQL> exec :x := 0;
SQL> exec :y := 100000;
--对包含绑定变量 x 和 y 的下述目标 SQL 语句使用 explain plan 命令
SQL> explain plan for select count(*) from t1 where object_id between :x and :y;
--使用 dbms_xplan.display 查看其执行计划
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 2351893609
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | FILTER | | | | | |
|* 3 | INDEX RANGE SCAN| IDX_T1 | 431 | 2155 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_NUMBER(:Y)>=TO_NUMBER(:X))
3 - access("OBJECT_ID">=TO_NUMBER(:X) AND "OBJECT_ID"<=TO_NUMBER(:Y))
--
从上述显示内容可知,使用 explain plan 命令得到的执行计划显示目标 SQL 走的是对索引 IDX_T1 的索引范围扫描。
--实际执行该目标 SQL
SQL> select count(*) from t1 where object_id between :x and :y;
COUNT(*)
----------
172248
--获取该目标 SQL 的真实执行计划
SQL> select * from table(dbms_xplan.display_cursor(null, null, 'allstats last peeked_binds'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 9dhu3xk2zu531, child number 1
-------------------------------------
select count(*) from t1 where object_id between :x and :y
Plan hash value: 1410530761
--------------------------------------------------
| Id | Operation | Name | E-Rows |
--------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | SORT AGGREGATE | | 1 |
|* 2 | FILTER | | |
|* 3 | INDEX FAST FULL SCAN| IDX_T1 | 172K|
--------------------------------------------------
Peeked Binds (identified by position):
--------------------------------------
1 - (NUMBER): 0
2 - (NUMBER): 100000
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(:Y>=:X)
3 - filter(("OBJECT_ID">=:X AND "OBJECT_ID"<=:Y))
Note
-----
- Warning: basic plan statistics not available. These are only collected when:
* hint 'gather_plan_statistics' is used for the statement or
* parameter 'statistics_level' is set to 'ALL', at session or system level
从上述显示内容可以看到,现在目标 SQL 的执行计划实际上走的是对索引 IDX_T1 的索引快速全扫描,这才是目标 SQL 真实的执行计划,即刚才使用的 explain plan 命令得到的执行计划是不准的。
获取执行计划的方式
在 Oracle 数据库里,我们通常可以使用如下这些方法得到目标 SQL 的执行计划。
explain plan
explain plan 的语法是依次执行如下两条命令:
SQL> explain plan for + 目标 SQL SQL> select * from table(dbms_xplan.display)
先使用 explain plan 命令对目标 SQL 做 explain,再使用 “select * from table(dbms_xplan.display)” 查看上述使用 explain plan 命令后得到的执行计划。这种方式得到的执行计划和在 PL/SQL Developer 中使用快捷键 F5 得到的执行计划是一样的。
SQL> set linesize 150;
SQL> set pagesize 1000;
SQL> set long 10000;
SQL> explain plan for select * from t1, t2 where t1.object_id = t2.object_id and t1.object_id in (18, 19);
已解释。
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 1838229974
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96 | 39744 | 686 (1)| 00:00:09 |
|* 1 | HASH JOIN | | 96 | 39744 | 686 (1)| 00:00:09 |
|* 2 | TABLE ACCESS FULL| T1 | 14 | 2898 | 343 (1)| 00:00:05 |
|* 3 | TABLE ACCESS FULL| T2 | 14 | 2898 | 343 (1)| 00:00:05 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
2 - filter("T1"."OBJECT_ID"=18 OR "T1"."OBJECT_ID"=19)
3 - filter("T2"."OBJECT_ID"=18 OR "T2"."OBJECT_ID"=19)
Note
-----
- dynamic sampling used for this statement (level=2)
已选择21行。
优点:
- 无需真正执行,快捷方便
缺点:
- 无法获取逻辑读 、物理读 、表访问次数 、递归调用次数等信息
- 并不是真实的执行计划,因为 SQL 语句并未真正执行
autotrace
| 序号 | 命令 | 描述 |
| 1 | set autotrace on | 显示结果集、执行计划和统计信息 |
| 2 | set autotrace on explain | 显示结果集和执行计划,不显示统计信息 |
| 3 | set autotrace traceonly | 显示执行计划和统计信息,不显示结果集 |
| 4 | set autotrace traceonly explain | 只显示执行计划 |
| 5 | set autotrace traceonly statistics | 只显示统计信息 |
SQL> set autotrace on;
SQL> select * from t1 inner join t2 on t1.object_id = t2.object_id where t1.object_id in (18, 19);
执行计划
----------------------------------------------------------
Plan hash value: 1838229974
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96 | 39744 | 686 (1)| 00:00:09 |
|* 1 | HASH JOIN | | 96 | 39744 | 686 (1)| 00:00:09 |
|* 2 | TABLE ACCESS FULL| T1 | 14 | 2898 | 343 (1)| 00:00:05 |
|* 3 | TABLE ACCESS FULL| T2 | 14 | 2898 | 343 (1)| 00:00:05 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
2 - filter("T1"."OBJECT_ID"=18 OR "T1"."OBJECT_ID"=19)
3 - filter("T2"."OBJECT_ID"=18 OR "T2"."OBJECT_ID"=19)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
7 recursive calls
0 db block gets
2616 consistent gets
0 physical reads
0 redo size
2955 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
关键字释义:
| 序号 | 关键字 | 说明 |
| 1 | recursive calls | 递归调用次数 |
| 2 | db block gets | 从磁盘获取的数据块 |
| 3 | consistent gets | 逻辑读 |
| 4 | physical reads | 物理读 |
| 5 | sorts (memory) | 内存排序次数 |
| 6 | sorts (disk) | 磁盘排序次数 |
优点:
- 可以看到逻辑读 、物理读 、递归调用次数
- 真实的执行计划
缺点:
- 无法看到表的访问次数、预估返回行、实际返回行等信息
DBMS_XPLAN 包
针对不同的应用场景,DBMS_XPLAN 包有如下几种方法:
| 方法 | 使用 | 数据源 |
| display | Explain plan | plan table |
| display_cursor | Real plan | shared pool 中的游标缓存 |
| display_awr | History | AWR 仓库基表 WRH\$_SQL_PLAN |
display
该方法是执行 “select * from table(dbms_xplan.display)”,这需要与 explain plan 命令配合使用,它用于查看使用 explain plan 命令后得到的执行计划。
SQL> explain plan for select * from t1, t2 where t1.object_id = t2.object_id and t1.object_id in (18, 19);
已解释。
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 1838229974
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 392 | 686 (1)| 00:00:09 |
|* 1 | HASH JOIN | | 2 | 392 | 686 (1)| 00:00:09 |
|* 2 | TABLE ACCESS FULL| T1 | 2 | 196 | 343 (1)| 00:00:05 |
|* 3 | TABLE ACCESS FULL| T2 | 2 | 196 | 343 (1)| 00:00:05 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
2 - filter("T1"."OBJECT_ID"=18 OR "T1"."OBJECT_ID"=19)
3 - filter("T2"."OBJECT_ID"=18 OR "T2"."OBJECT_ID"=19)
已选择17行。
display_cursor
该方法有三个参数,参数格式如下:
| 序号 | 参数 | 描述 | |
| 1 | SQL_ID | 如果 SQL_ID 设置为 NULL 则默认为之前运行的一条 SQL 语句 | |
| 2 | Child Number | 如果 Child Number 设置为 NULL 则返回所有子游标的执行计划 | |
| 3 | Format | all stats | iostats + memstats |
| iostats | 显示累计执行的 IO 统计信息(Buffers、Reads) | ||
| memstats | 显示累计执行的 PGA 使用信息(OMem、1Mem、Used-Mem) | ||
| last | 仅显示最后一次执行的统计信息 | ||
| advanced | 显示 Query Block Name、Outline Data、Column Projection Information 等信息 | ||
| peeked_binds | 打印解析时使用的绑定变量 | ||
Format 参数可组合使用,使用的方式如下(需注意每个关键词后面要加空格):
'allstats last' 'advanced allstats last' 'advanced allstats last peeked_binds'
--statistics_level 默认值为 typical,不设置则无法获得 A-ROWS 等信息 SQL> alter session set statistics_level = all; SQL> select * from t1 inner join t2 on t1.object_id = t2.object_id where t1.object_id in (18, 19); SQL> select * from table(dbms_xplan.display_cursor(null, null, 'advanced allstats last')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 97ncdvby18nut, child number 1 ------------------------------------- select * from t1 inner join t2 on t1.object_id = t2.object_id where t1.object_id in (18, 19) Plan hash value: 1838229974 ------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 686 (100)| | 2 |00:00:00.02 | 2469 | | | | |* 1 | HASH JOIN | | 1 | 2 | 392 | 686 (1)| 00:00:09 | 2 |00:00:00.02 | 2469 | 874K| 874K| 516K (0)| |* 2 | TABLE ACCESS FULL| T1 | 1 | 2 | 196 | 343 (1)| 00:00:05 | 2 |00:00:00.01 | 1234 | | | | |* 3 | TABLE ACCESS FULL| T2 | 1 | 2 | 196 | 343 (1)| 00:00:05 | 2 |00:00:00.01 | 1235 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- 1 - SEL$58A6D7F6 2 - SEL$58A6D7F6 / T1@SEL$1 3 - SEL$58A6D7F6 / T2@SEL$1 Outline Data ------------- /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.4') DB_VERSION('11.2.0.4') OPT_PARAM('star_transformation_enabled' 'true') ALL_ROWS OUTLINE_LEAF(@"SEL$58A6D7F6") MERGE(@"SEL$1") OUTLINE(@"SEL$2") OUTLINE(@"SEL$1") FULL(@"SEL$58A6D7F6" "T1"@"SEL$1") FULL(@"SEL$58A6D7F6" "T2"@"SEL$1") LEADING(@"SEL$58A6D7F6" "T1"@"SEL$1" "T2"@"SEL$1") USE_HASH(@"SEL$58A6D7F6" "T2"@"SEL$1") END_OUTLINE_DATA */ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID") 2 - filter(("T1"."OBJECT_ID"=18 OR "T1"."OBJECT_ID"=19)) 3 - filter(("T2"."OBJECT_ID"=18 OR "T2"."OBJECT_ID"=19)) Column Projection Information (identified by operation id): ----------------------------------------------------------- 1 - (#keys=1) "T1"."OBJECT_ID"[NUMBER,22], "T2"."OBJECT_ID"[NUMBER,22], "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."SUBOBJECT_NAME"[VARCHAR2,30], "T1"."EDITION_NAME"[VARCHAR2,30], "T1"."DATA_OBJECT_ID"[NUMBER,22], "T1"."OBJECT_TYPE"[VARCHAR2,19], "T1"."CREATED"[DATE,7], "T1"."LAST_DDL_TIME"[DATE,7], "T1"."TIMESTAMP"[VARCHAR2,19], "T1"."STATUS"[VARCHAR2,7], "T1"."TEMPORARY"[VARCHAR2,1], "T1"."GENERATED"[VARCHAR2,1], "T1"."SECONDARY"[VARCHAR2,1], "T1"."NAMESPACE"[NUMBER,22], "T2"."OWNER"[VARCHAR2,30], "T2"."OBJECT_NAME"[VARCHAR2,128], "T2"."SUBOBJECT_NAME"[VARCHAR2,30], "T2"."EDITION_NAME"[VARCHAR2,30], "T2"."DATA_OBJECT_ID"[NUMBER,22], "T2"."OBJECT_TYPE"[VARCHAR2,19], "T2"."CREATED"[DATE,7], "T2"."LAST_DDL_TIME"[DATE,7], "T2"."TIMESTAMP"[VARCHAR2,19], "T2"."STATUS"[VARCHAR2,7], "T2"."TEMPORARY"[VARCHAR2,1], "T2"."GENERATED"[VARCHAR2,1], "T2"."SECONDARY"[VARCHAR2,1], "T2"."NAMESPACE"[NUMBER,22] 2 - "T1"."OWNER"[VARCHAR2,30], "T1"."OBJECT_NAME"[VARCHAR2,128], "T1"."SUBOBJECT_NAME"[VARCHAR2,30], "T1"."OBJECT_ID"[NUMBER,22], "T1"."DATA_OBJECT_ID"[NUMBER,22], "T1"."OBJECT_TYPE"[VARCHAR2,19], "T1"."CREATED"[DATE,7], "T1"."LAST_DDL_TIME"[DATE,7], "T1"."TIMESTAMP"[VARCHAR2,19], "T1"."STATUS"[VARCHAR2,7], "T1"."TEMPORARY"[VARCHAR2,1], "T1"."GENERATED"[VARCHAR2,1], "T1"."SECONDARY"[VARCHAR2,1], "T1"."NAMESPACE"[NUMBER,22], "T1"."EDITION_NAME"[VARCHAR2,30] 3 - "T2"."OWNER"[VARCHAR2,30], "T2"."OBJECT_NAME"[VARCHAR2,128], "T2"."SUBOBJECT_NAME"[VARCHAR2,30], "T2"."OBJECT_ID"[NUMBER,22], "T2"."DATA_OBJECT_ID"[NUMBER,22], "T2"."OBJECT_TYPE"[VARCHAR2,19], "T2"."CREATED"[DATE,7], "T2"."LAST_DDL_TIME"[DATE,7], "T2"."TIMESTAMP"[VARCHAR2,19], "T2"."STATUS"[VARCHAR2,7], "T2"."TEMPORARY"[VARCHAR2,1], "T2"."GENERATED"[VARCHAR2,1], "T2"."SECONDARY"[VARCHAR2,1], "T2"."NAMESPACE"[NUMBER,22], "T2"."EDITION_NAME"[VARCHAR2,30] 已选择71行。
关键字释义:
| 序号 | 关键字 | 说明 |
| 1 | Starts | 该 SQL 执行的次数(表的访问次数) |
| 2 | E-Rows | 执行计划预计返回的行数 |
| 3 | Cost (%CPU) | 成本值 |
| 4 | A-Rows | 执行计划实际返回的行数 |
| 5 | A-Time | 每一步实际执行的时间 |
| 6 | Buffers | 每一步实际执行的逻辑读或一致性读 |
| 7 | OMem | 当前操作完成所有内存工作区(Work Aera)操作所总共使用私有内存(PGA)中工作区的大小 |
| 8 | 1Mem | 当工作区大小无法满足操作所需的大小时,需要将部分数据写入临时磁盘空间中,该列数据为语句最后一次执行中,单次写磁盘所需要的内存大小 |
| 9 | User-Mem | 语句最后一次执行中,当前操作所使用的内存工作区大小 |
优点:
- 可以看出 SQL 执行次数(表访问次数)
- 可以看出清晰地从
E-Rows和A-Rows中得到预测的行数和真实的行数,从而可以准确判断 Oracle 评估是否准确 - 可以看出
Buffers逻辑读大小 - 真实执行计划
缺点:
- 必须要等到语句真正执行完毕后,才可以出结果
- 无法查看递归调用次数 、排序次数
display_awr
该方法有用来查看指定 SQL 的所有历史执行计划。
10046 事件
SQL> set linesize 120; SQL> set pagesize 1000; SQL> set long 5000; SQL> alter session set statistics_level=typical;
- 激活 10046
SQL> alter session set events '10046 trace name context forever, level 12';
- 执行目标 SQL
SQL> select * from t1 inner join t2 on t1.object_id = t2.object_id where t1.object_id in (18, 19);
- 关闭 10046
SQL> alter session set events '10046 trace name context off';
- 查看 trace 文件路径
SQL> select distinct(m.sid), p.pid, p.tracefile from v$mystat m, v$session s, v$process p where m.sid = s.sid and s.paddr = p.addr;
SID PID TRACEFILE
---------- ---------- --------------------------------------------------------------------------------
108 29 D:\APP\diag\rdbms\orcl\orcl\trace\orcl_ora_13088.trc
- 利用 tkprof 格式化输入
SQL> exit
C:\Windows\System32>tkprof D:\APP\diag\rdbms\orcl\orcl\trace\orcl_ora_13088.trc D:\13088_trace.trc
********************************************************************************
SQL ID: dwx6dsc2cb4zz Plan Hash: 1838229974
select *
from
t1 inner join t2 on t1.object_id = t2.object_id where t1.object_id in (18,
19)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 2 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.01 0.04 1922 2470 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.01 0.05 1922 2472 0 2
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 83
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
2 2 2 HASH JOIN (cr=2470 pr=1922 pw=0 time=24897 us cost=686 size=39744 card=96)
2 2 2 TABLE ACCESS FULL T1 (cr=1235 pr=973 pw=0 time=40 us cost=343 size=2898 card=14)
2 2 2 TABLE ACCESS FULL T2 (cr=1235 pr=949 pw=0 time=227 us cost=343 size=2898 card=14)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 2 0.00 0.00
SQL*Net message from client 2 0.03 0.03
db file scattered read 111 0.00 0.02
db file sequential read 8 0.00 0.00
********************************************************************************
优点:
- 可以看出 SQL 语句对应的等待事件
- 可以看出处理的行数,产生的物理读和逻辑读
- 可以看出解析时间和执行时间
缺点:
- 无法判断表被访问了多少次
- 无法看到条件谓词部分
AWR 报告
- 运行AWR脚本
SQL> @ORACLE_HOME/RDBMS/ADMIN/awrsqrpt.sql
-
选择快照的 begin_snap 和 end_snap
-
输入SQL_Id 的值
执行计划的顺序
可以使用如下口诀来查看目标 SQL 执行计划的执行顺序:
-
从顶部开始;
-
在行源中向下移动,直至找到一个没有子节点的节点,首先执行此节点;
-
查看此行源的同级行源(缩进一样),继续向下查找没有子节点的节点,接着执行此节点;
-
执行完子行源后,接着执行父行源;
-
在计划中不断上移,直至用完所有行源为止。
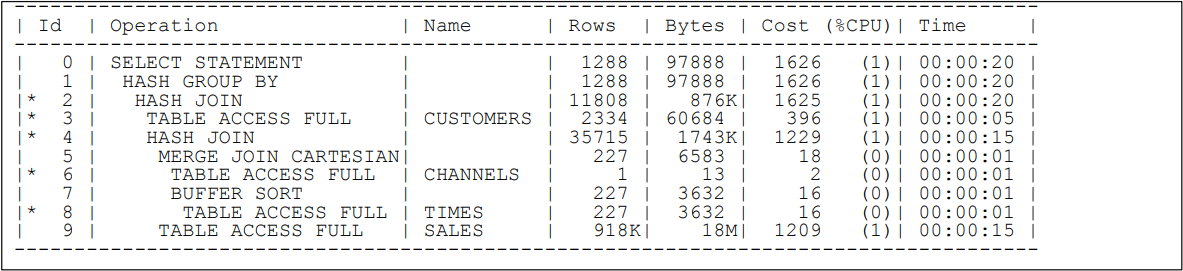
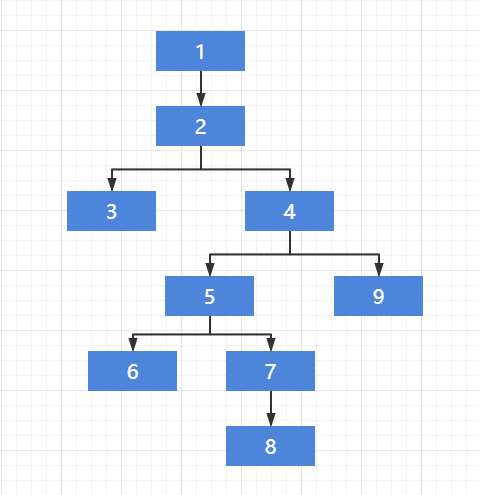
根据上图可知,该执行计划的执行顺序为:3 - 6 - 8 - 7 - 5 - 9 - 4 - 2 - 1
条件谓词
执行计划信息中,有两个重要的条件谓词 filter 和 access。
谓词 access 多用于使用索引访问的场景,所谓 Access 即是不遍历全量的数据,而利用对应的查询条件或者约束来驱动访问索引。
谓词 filter 多用于无法使用索引访问的场景,例如对整张表全表扫描的过程中,对于每一条记录做识别,看是否符合过滤相关的条件。filter 一般没有驱动作用,只起到过滤的作用。
SQL> create table t3 as select * from dba_objects; SQL> create table t4 as select * from dba_objects; SQL> create table t5 as select * from dba_objects; SQL> create index idx_t3 on t3(object_id); SQL> create index idx_t4 on t4(object_id, object_name);
全表扫描
SQL> set autotrace traceonly;
SQL> select * from t5 where object_id = 100;
执行计划
----------------------------------------------------------
Plan hash value: 2002323537
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15 | 3105 | 379 (1)| 00:00:05 |
|* 1 | TABLE ACCESS FULL| T5 | 15 | 3105 | 379 (1)| 00:00:05 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID"=100)
无索引,走全表扫描,谓词条件在这里只是起到数据过滤的作用,所以使用了 filter
索引扫描
SQL> select * from t3 where t3.object_id = 100;
执行计划
----------------------------------------------------------
Plan hash value: 636101163
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 207 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T3 | 1 | 207 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T3 | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T3"."OBJECT_ID"=100)
有索引,谓词条件影响到数据访问的路径,选择了索引,所以用 access
执行计划分类
执行计划目录
| 序号 | 执行计划分类 | 明细 |
| 1 | 表访问相关执行计划 | 全表扫描 |
| 2 | USER ROWID 扫描 | |
| 3 | INDEX ROWID 扫描 | |
| 4 | 索引相关执行计划 | 索引唯一扫描 |
| 5 | 索引范围扫描 | |
| 6 | 索引全扫描 | |
| 7 | 索引快速全扫描 | |
| 8 | 索引跳跃扫描 | |
| 9 | 表连接相关执行计划 | 嵌套循环连接 |
| 10 | 哈希连接 | |
| 11 | 排序合并连接 | |
| 12 | 反连接 | |
| 13 | 半连接 | |
| 14 | 其它执行计划 | AND-EQUAL |
| 15 | VIEW | |
| 16 | FILTER | |
| 17 | SORT | |
| 18 | UNION/UNION ALL | |
| 19 | CONNECT BY |
表访问相关执行计划
- 全表扫描(TABLE ACCESS FULL)
TABLE ACCESS FULL
- ROWID 扫描(TABLE ACCESS BY USER ROWID)
TABLE ACCESS BY USER ROWID
- ROWID 扫描(TABLE ACCESS BY INDEX ROWID)
TABLE ACCESS BY INDEX ROWID
索引相关执行计划
- 索引唯一扫描(INDEX UNIQUE SCAN)
INDEX UNIQUE SCAN 说明: 至多只会返回一条记录
- 索引范围扫描(INDEX RANGE SCAN)
INDEX RANGE SCAN 说明: 可能返回多条记录
- 索引全扫描(INDEX FULL SCAN)
INDEX FULL SCAN 说明: 1. 按顺序扫描目标索引所有叶子块的所有索引行 2. 返回记录有序(索引键值列顺序)
- 索引快速全扫描(INDEX FAST FULL SCAN)
INDEX FAST FULL SCAN 特性: 1. 按顺序扫描目标索引所有叶子块的所有索引行,但可以使用多块读 2. 返回记录不一定有序 3. 不能回表 4. 其原理就是将索引当成表来操作了
- 索引跳跃扫描(INDEX SKIP SCAN)
INDEX SKIP SCAN 特性: 1. 用于复合索引且仅以非前导列做查询条件 2. 前导列distinct值大小会影响索引跳跃扫描的效率
表连接相关执行计划
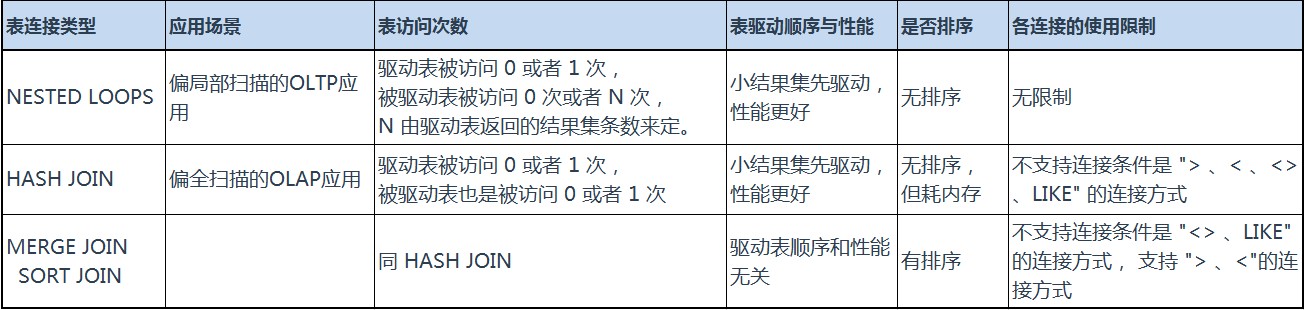
- 嵌套循环连接(NESTED LOOPS)
NESTED LOOPS 说明: 1. 驱动表的限制条件要考虑建立索引 2. 被驱动表的限制条件要考虑建立索引 3. 小结果集表作为驱动表, 大结果集表作为被驱动表。
- 哈希连接(HASH JOIN)
HASH JOIN 说明: 1. 两表的限制条件有索引(根据返回结果集数量) 2. 小结果集表作为驱动表, 大结果集的表作为被驱动表 3. 尽量保证PGA能容纳Hash运算。
- 排序合并连接(MERGE JOIN & SORT JOIN)
MERGE JOIN & SORT JOIN 说明: 1. 两表的限制条件有索引(根据返回结果集数量) 2. 避免SQL语句获取多余列的值导致排序尺寸过大 3. 确保PGA能完成排序,避免磁盘排序。
- 反连接(ANTI)
HASH JOIN ANTI MERGE JOIN ANTI NESTED LOOPS ANTI
- 半连接(SEMI)
HASH JOIN SEMI MERGE JOIN SEMI NESTED LOOPS SEMI
其它执行计划
- AND-EQUAL(INDEX MERGE) HERE 条件中出现了多个针对不同单列的等值条件,并且这些列上都有单键值的索引。
SQL> drop table t purge;
SQL> create table t as select * from dba_objects;
SQL> create index idx_t1 on t(object_id);
SQL> create index idx_t2 on t(data_object_id);
SQL> set autotrace traceonly;
SQL> select /*+ and_equal(t idx_t1 idx_t2) */ object_id, data_object_id from t where t.object_id = 20 and t.data_object_id = 2;
执行计划
----------------------------------------------------------
Plan hash value: 1275876533
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 7 | 182 | 2 (0)| 00:00:01 |
|* 1 | AND-EQUAL | | | | | |
|* 2 | INDEX RANGE SCAN| IDX_T2 | 12 | | 1 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN| IDX_T1 | 12 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("T"."OBJECT_ID"=20 AND "T"."DATA_OBJECT_ID"=2)
2 - access("T"."DATA_OBJECT_ID"=2)
3 - access("T"."OBJECT_ID"=20)
- VIEW Oracle 在处理包含视图的SQL时,根据该视图是否能做视图合并(View Merging),其对应的执行计划有:
# 1. 可以做视图合并 则Oracle在执行该SQL语句时可以直接针对该视图的基表(源表),此时SQL的执行计划很可能不会出现关键字 "VIEW"。 # 2. 不能做视图合并 则Oracle会把该视图看做一个整体并单独地执行它,此时SQL的执行计划会出现关键字 "VIEW"。
-
FILTER FILTER 是一种特殊的执行计划,它所对应的执行步骤是如下三步: a. 得到一个驱动结果集;
b. 根据一定的过滤条件从上述驱动结果集中过滤不满足条件的记录;
c. 结果集中剩下的记录就会返回给最终用户或者继续参与下一个执行步骤。 -
SORT SORT就是排序的意思,常会以组合形式出现。
1. SORT UNIQUE 排序 + 去重 2. SORT JOIN 排序合并 3. SORT ORDER BY 单纯的排序 4. SORT GROUP BY 排序 + 分组
-
UNION/UNION ALL UNION/UNION ALL 表示对两个结果集进行合并。
-
CONNECT BY 层次查询所对应的关键字。
通过查看执行计划建立索引
执行如下目标 SQL 语句,并查看其执行计划。
SQL> create table t1 as select * from emp; SQL> create table t2 as select * from dept; declare begin execute immediate 'alter session set statistics_level = ALL'; --待执行的业务SQL语句 for x in ( select t1.ename, t1.job, t2.dname from t1, t2 where t1.deptno = t2.deptno and t1.sal < 2000 ) loop null; end loop; for y in ( select p.plan_table_output from table(dbms_xplan.display_cursor(null, null, 'advanced allstats last')) p ) loop dbms_output.put_line(y.plan_table_output); end loop; rollback; end; / SQL_ID 5jzza1g2s2qsh, child number 0 ------------------------------------- SELECT T1.ENAME, T1.JOB, T2.DNAME FROM T1, T2 WHERE T1.DEPTNO = T2.DEPTNO AND T1.SAL < 2000 Plan hash value: 2959412835 ------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 6 (100)| | 8 |00:00:00.01 | 6 | | | | |* 1 | HASH JOIN | | 1 | 8 | 488 | 6 (0)| 00:00:01 | 8 |00:00:00.01 | 6 | 1599K| 1599K| 1071K (0)| | 2 | TABLE ACCESS FULL| T2 | 1 | 4 | 88 | 3 (0)| 00:00:01 | 4 |00:00:00.01 | 3 | | | | |* 3 | TABLE ACCESS FULL| T1 | 1 | 8 | 312 | 3 (0)| 00:00:01 | 8 |00:00:00.01 | 3 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- 1 - SEL$1 2 - SEL$1 / T2@SEL$1 3 - SEL$1 / T1@SEL$1 Outline Data ------------- /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.4') DB_VERSION('11.2.0.4') OPT_PARAM('star_transformation_enabled' 'true') ALL_ROWS OUTLINE_LEAF(@"SEL$1") FULL(@"SEL$1" "T2"@"SEL$1") FULL(@"SEL$1" "T1"@"SEL$1") LEADING(@"SEL$1" "T2"@"SEL$1" "T1"@"SEL$1") USE_HASH(@"SEL$1" "T1"@"SEL$1") END_OUTLINE_DATA */ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."DEPTNO"="T2"."DEPTNO") 3 - filter("T1"."SAL"<2000) Column Projection Information (identified by operation id): ----------------------------------------------------------- 1 - (#keys=1) "T2"."DNAME"[VARCHAR2,14], "T1"."ENAME"[VARCHAR2,10], "T1"."JOB"[VARCHAR2,9] 2 - "T2"."DEPTNO"[NUMBER,22], "T2"."DNAME"[VARCHAR2,14] 3 - "T1"."ENAME"[VARCHAR2,10], "T1"."JOB"[VARCHAR2,9], "T1"."DEPTNO"[NUMBER,22] Note ----- - dynamic sampling used for this statement (level=2)
根据上述执行计划显示的内容,有些 Id 列前面有 “*” 号,这表示发生了谓词过滤、或者发生了 HASH 连接、或者走了索引。Id=1 前面有 “*” 号,它是 HASH 连接的 “*” 号,我们观察对应的谓词过滤信息就能知道是哪两个表进行的 HASH 连接,而且能知道是对哪些列进行的 HASH 连接,根据上述执行计划中的 Predicate Information 部分可知是 T1 表的 deptno 列与 T2 表的 deptno 列进行 HASH 连接的。
Id=3 前面也有 “*” 号,这里表示表 T1 有谓词过滤,它的过滤条件就是 Id=3 的谓词过滤信息,也就是 “e.sal < 2000”。
Id=2 前面没有 “*” 号,那么说明 T2 表没有谓词过滤条件。
- TABLE ACCESS FULL 前面没有 “*” 号的处理方式
如果表很小,那么我们不需理会,小表不会产生性能问题;如果表很大,那么我们要先询问开发人员及检查 SQL 语句是否漏写了过滤条件。如果访问的列不多,就可以考虑把这些列组合起来,建立一个组合索引,通过利用 INDEX FAST FULL SCAN 代替 TABLE ACCESS FULL。另外也可以通过其他方法优化,必须开启并行查询,或者更改表连接方式,让大表作为嵌套循环的被驱动表。
- TABLE ACCESS FULL 前面有 “*” 号的处理方式
如果表很小,那么我们不需理会;如果表很大,可以使用 “select count(*) from table_name”,查看表有多少行数据,然后通过 “select count(*) from table_name where ...” 对应的谓词过滤条件,查看施加谓词过滤条件后返回多少行数据。如果返回的行数在表总行数的 5% 以内,我们可以考虑在列上建立索引。如果已经存在索引,但是没走索引,这时我们要检查统计信息,特别是直方图信息。如果统计信息已经收集过了,我们可以使用 Hint 强制走索引。
如果有多个谓词过滤条件,我们需要建立组合索引并且将选择性高的列放在前面,选择性低的列放放在后面。
- TABLE ACCESS BY INDEX ROWID 前面有 “*” 号的处理方式
TABLE ACCESS BY INDEX ROWID 前面有 “*” 号,表示回表再过滤。回表再过滤说明数据没有在索引中过滤干净。
SQL> create table test as select * from dba_objects;
SQL> create index idx_t1 on test(object_name);
SQL> set autotrace on;
SQL> select /*+ index(idx_t1 test) */ * from test where object_name like 'V_$%' and owner = 'SCOTT';
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 2044707838
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 49 | 10143 | 236 (0)| 00:00:03 |
|* 1 | TABLE ACCESS BY INDEX ROWID| TEST | 49 | 10143 | 236 (0)| 00:00:03 |
|* 2 | INDEX RANGE SCAN | IDX_T1 | 519 | | 5 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OWNER"='SCOTT')
2 - access("OBJECT_NAME" LIKE 'V_$%')
filter("OBJECT_NAME" LIKE 'V_$%')
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
20 recursive calls
0 db block gets
473 consistent gets
10 physical reads
0 redo size
1344 bytes sent via SQL*Net to client
509 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
当 TABLE ACCESS BY INDEX ROWID 前面有 “*” 号时,可以将 “*” 号下面的过滤条件包含在索引中,这样可以减少回表次数,提升查询性能。即将上述执行计划 Predicate Information 中 filter("OWNER"='SCOTT') 包含在索引中。
SQL> create index idx_t2 on test(owner, object_name);
SQL> select /*+ index(idx_t2 test) */ * from test where object_name like 'V_$%' and owner = 'SCOTT';
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 2561606646
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 49 | 10143 | 6 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 49 | 10143 | 6 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T2 | 4 | | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER"='SCOTT' AND "OBJECT_NAME" LIKE 'V_$%')
filter("OBJECT_NAME" LIKE 'V_$%')
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
81 consistent gets
2 physical reads
0 redo size
1344 bytes sent via SQL*Net to client
509 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
参考资料
《基于 Oracle 的 SQL 优化 -- 崔华》
《收获,不止SQL优化 -- 梁敬彬》
《SQL 优化核心思想 -- 罗炳森》
原创文章,转载请注明出处:http://www.opcoder.cn/article/4/