Pandas 提供了大量的数据计算函数,可以实现求和、求均值、求最大值、求最小值、求中位数、求众数、求方差、标准差等。从而使得数据统计变得简单、高效。
数据计算
| 序号 | 函数 | 描述 |
| 1 | sum() | 求和 |
| 2 | mean() | 求均值 |
| 3 | max() | 求最大值 |
| 4 | min() | 求最小值 |
| 5 | median() | 求中位数 |
| 6 | mode() | 求众数 |
| 7 | var() | 求方差 |
| 8 | std() | 求标准差 |
| 9 | quantile() | 求分位数 |
- sum()
在 Python 中通过调用 DataFrame 对象的 sum 函数实现行/列数据的求和运算,语法如下:
DataFrame.sum([axis, skipna, level, ...])
参数说明:
axis: axis=0表示按列相加;axis=1表示按行相加,默认值为0,表示按列相加 skipna: skip=1,表示NaN值自动转换为0;skipna=0,表示NaN值不自动转换,默认NaN值自动转换为0 level: 表示索引层级 返回值: 返回Series对象,一组含有行/列小计的数据
使用示例:
import pandas as pd data = [[110,105,99], [105,88,115], [109,120,130]] index = [1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按行相加,计算 “语文”、“数学”、“英语” 的总成绩 df['总成绩'] = df.sum(axis=1) print(df) 语文 数学 英语 总成绩 1 110 105 99 314 2 105 88 115 308 3 109 120 130 359
- mean()
在 Python 中通过调用 DataFrame 对象的 mean 函数实现行/列数据的平均值运算,语法如下:
DataFrame.mean([axis, skipna, level, ...])
参数说明:
axis: axis=0表示按列求平均值;axis=1表示按行求平均值,默认值为0,表示按列求平均值 skipna: skip=1,表示NaN值自动转换为0;skipna=0,表示NaN值不自动转换,默认NaN值自动转换为0 level: 表示索引层级 返回值: 返回Series对象,一组含有行/列平均值的数据
使用示例:
import pandas as pd data = [[110,105,99], [105,88,115], [109,120,130], [112,115]] index = [0,1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按列求平均值,计算 “语文”、“数学”、“英语” 的平均值,忽略索引 new = df.mean() df = df.append(new,ignore_index=True) print(df) 语文 数学 英语 0 110.0 105.0 99.000000 1 105.0 88.0 115.000000 2 109.0 120.0 130.000000 3 112.0 115.0 NaN 4 109.0 107.0 114.666667
- max()
在 Python 中通过调用 DataFrame 对象的 max 函数实现行/列数据的最大值运算,语法如下:
DataFrame.max([axis, skipna, level, ...])
参数说明:
axis: axis=0表示按列求最大值;axis=1表示按行求最大值,默认值为0,表示按列求最大值 skipna: skip=1,表示NaN值自动转换为0;skipna=0,表示NaN值不自动转换,默认NaN值自动转换为0 level: 表示索引层级 返回值: 返回Series对象,一组含有行/列最大值的数据
使用示例:
import pandas as pd data = [[110,105,99], [105,88,115], [109,120,130], [112,115]] index = [0,1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按列求最大值,计算 “语文”、“数学”、“英语” 的最大值,忽略索引 new = df.max() df = df.append(new,ignore_index=True) print(df) 语文 数学 英语 0 110.0 105.0 99.0 1 105.0 88.0 115.0 2 109.0 120.0 130.0 3 112.0 115.0 NaN 4 112.0 120.0 130.0
- min()
在 Python 中通过调用 DataFrame 对象的 min 函数实现行/列数据的最小值运算,语法如下:
DataFrame.min([axis, skipna, level, ...])
参数说明:
axis: axis=0表示按列求最小值;axis=1表示按行求最小值,默认值为0,表示按列求最小值 skipna: skip=1,表示NaN值自动转换为0;skipna=0,表示NaN值不自动转换,默认NaN值自动转换为0 level: 表示索引层级 返回值: 返回Series对象,一组含有行/列最小值的数据
使用示例:
import pandas as pd data = [[110,105,99], [105,88,115], [109,120,130], [112,115]] index = [0,1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按列求最小值,计算 “语文”、“数学”、“英语” 的最小值,忽略索引 new = df.min() df = df.append(new,ignore_index=True) print(df) 语文 数学 英语 0 110.0 105.0 99.0 1 105.0 88.0 115.0 2 109.0 120.0 130.0 3 112.0 115.0 NaN 4 105.0 88.0 99.0
- median()
在 Python 中通过调用 DataFrame 对象的 median 函数实现行/列数据的中位数运算,语法如下:
DataFrame.median([axis=None, skipna=None, level=None, numeric_only=None, **kwargs])
参数说明:
axis: axis=0表示按列求中位数;axis=1表示按行求中位数,默认值为None skipna: 布尔值,默认为True,表示排除NA/空值。如果整个行/列均为NA,则结果为NA level: 表示索引层级,默认值为None numeric_only: 仅数字,布尔型,默认为None **kwargs: 要传递给函数的附加关键字参数 返回值: 返回Series或DataFrame对象
使用示例:
import pandas as pd data = [[110,120,110], [135,130,130], [110,120,130], [120,130]] index = [0,1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) print(df.median()) 语文 115.0 数学 125.0 英语 130.0 dtype: float64
- mode()
在 Python 中通过调用 DataFrame 对象的 mode 函数实现行/列数据的众数运算,语法如下:
DataFrame.mode([axis=0, numeric_only=False, dropna=True)
参数说明:
axis: axis=0表示按列求众数;axis=1表示按行求众数,默认按列求众数 numeric_only: 仅数字,布尔型,默认为False,如果为True,则仅适用于数字列 dropna: 是否删除缺失值,布尔型,默认为True 返回值: 返回DataFrame对象
使用示例:
import pandas as pd data = [[110,120,110], [130,130,130], [130,120,130]] index = [0,1,2] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按列计算,求三科成绩的众数 print(df.mode()) 语文 数学 英语 0 130 120 130 # 按行计算,,求每一行的众数 print(df.mode(axis=1)) 0 110 1 130 2 130 # 按列计算,求“数学”的众数 print(df['数学'].mode()) 0 120 dtype: int64
- var()
方差主要用于衡量一组数据的离散程度,即各组数据与它们的平均数的差的平方,那么用这个结果来衡量这组数据的波动大小,并把它叫做这组数据的方差,方差越小越稳定。
在 Python 中,通过调用 DataFrame 对象的 var 函数可以实现方差运算,语法如下:
DataFrame.var(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
参数说明:
axis: axis=0表示按列求中位数;axis=1表示按行求中位数,默认值为None skipna: 布尔型,表示计算结果是否排除了NaN/Null值,默认为None level: 表示索引层级,默认值为None ddof: 整型,默认为1,自由度,计算中使用的除数是N-ddof,其中N表示元素的数量 numeric_only: 仅数字,布尔型,默认为None **kwargs: 要传递给函数的附加关键字参数 返回值: 返回Series或DataFrame对象
使用示例:
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) data = [[110,113,102,105,108], [118,98,119,85,118]] index = ['小明', '小红'] columns = ['物理1','物理2','物理3','物理4','物理5'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按行计算,求方差 print(df.var(axis=1)) 小明 18.3 小红 237.3 dtype: float64
注: Pandas 中计算的方差为无偏样本方差(即方差和/样本数-1),而 Numpy 中计算的方差就是样本方差本身(即方差和/样本数)。
- std()
标准差又称均方差,是方差的平方根,用来表示数据的离散程度。
在 Python 中,通过调用 DataFrame 对象的 std 函数可以实现标准差运算,语法如下(与方差一样):
DataFrame.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
使用示例:
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) data = [[110,120,110], [130,130,130], [130,120,130]] index = [1,2,3] columns = ['语文','数学','英语'] df = pd.DataFrame(data=data, index=index, columns=columns) # 按列计算,求标准差 print(df.std()) 语文 11.547005 数学 5.773503 英语 11.547005 dtype: float64
- quantile()
分位数也称分位点,它以概率为依据将数据分割为几个等分,常用的有二分位、四分位、百分位等。分位数是数据分析中常用的一个统计量,经过抽样得到一个样本值。
在 Python 中,通过调用 DataFrame 对象的 quantile 函数可以实现分位数运算,语法如下:
DataFrame.quantile(q=0.5, axis=0, numeric_only=True, interpolation='linear')
参数说明:
q: 浮点型或数组,默认为0.5(50%分位数),其值在0~1之间 axis: axis=0表示按列求分位数;axis=1表示按行求分位数,默认值为0 numeric_only: 仅数字,布尔型,默认为True interpolation: 内插值,可选参数,用于指定要使用的插值方法,当期望的分位数位于两个数据点i和j之间时: - 线性: i+(j-i)*分数,其中分数是指被i和j包围的小数部分 - 较低: i - 较高: j - 最近: i或j都以最近者为准 - 中点: (i+j)/2 返回值: 返回Series或DataFrame对象
使用示例:
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) data = [120,89,98,78,65,102,112,56,79,45] columns = ['数学'] df = pd.DataFrame(data=data, columns=columns) # 通过分位数确定被淘汰的35%的学生(计算35%的分位数) x = df['数学'].quantile(0.35) # 输出淘汰学生 print(df[df['数学'] <= x]) 数学 3 78 4 65 7 56 9 45
如果 numeric_only=False,将计算日期、时间和时间增量数据的分位数
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) df = pd.DataFrame({'A':[1,2], 'B':[pd.Timestamp('2019'),pd.Timestamp('2020')], 'C':[pd.Timedelta('1 days'),pd.Timedelta('2 days')]}) print(df.quantile(0.5,numeric_only=False)) A 1.5 B 2019-07-02 12:00:00 C 1 days 12:00:00 Name: 0.5, dtype: object
数据格式化
当我们在进行数据处理时,尤其是在数据计算中应用求均值后,发现结果中的小数位数增加了许多。此时就需要对数据进行格式化,以增加数据的可读性。例如,保留小数点位数、百分号、千位分隔符等。
设置小数位数
设置小数位数,主要使用 DataFrame 对象中的 round 函数,该函数可以实现四舍五入,而它的 decimals 参数则用于设置保留小数的位数,设置后的数据类型不会发生变化,依然是浮点型。语法如下:
DataFrame.round(decimals=0, *args, **kwargs)
参数说明:
decimals: 每一列四舍五入的小数位数,整型、字典或Series对象。如果是整数,则将每一列四舍五入到相同的位置;否则,将dict和Series舍入到可变数目的位置。如果小数是类似于字典的,那么列名应该在键中;如果小数是级数,列名应该在索引中。没有包含在小数中的任何列都保持原样,非输入列的小数元素将被忽略 *args: 附加的关键字参数 **kwargs: 附加的关键字参数 返回值: 返回DataFrame对象
- 四舍五入保留指定的小数位数
import pandas as pd import numpy as np df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5']) # 保留小数点后两位 print(df.round(2)) A1 A2 A3 A4 A5 0 0.93 0.44 0.53 0.87 0.79 1 0.06 0.48 0.96 0.14 0.64 2 0.27 0.12 0.25 0.35 0.13 3 0.65 0.22 0.06 0.85 0.16 4 0.57 0.44 0.48 0.97 0.72 # A1列保留小数点后一位、A2列保留小数点后两位 print(df.round({'A1':1, 'A2':2})) A1 A2 A3 A4 A5 0 0.9 0.44 0.530376 0.868485 0.787129 1 0.1 0.48 0.958289 0.141966 0.635177 2 0.3 0.12 0.254841 0.349205 0.128636 3 0.6 0.22 0.057434 0.847991 0.160169 4 0.6 0.44 0.477255 0.968664 0.717014
- 自定义函数保留小数位数
import pandas as pd import numpy as np df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5']) print(df.applymap(lambda x:'%.2f' %x)) A1 A2 A3 A4 A5 0 0.25 0.91 0.67 0.05 0.98 1 0.64 0.30 0.75 0.50 0.27 2 0.94 0.58 0.96 0.98 0.10 3 0.60 0.16 0.16 0.98 0.47 4 0.39 0.85 0.87 0.12 0.42
注: 经过自定义函数处理后的数据将不再是浮点型而是对象型,如果后续计算则首先应该将数据类型进行转换。
设置百分比
在数据分析过程中,有时需要百分比数据。利用自定义函数将数据进行格式化处理,主要使用 apply 函数与 format 函数。
import pandas as pd import numpy as np df =pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5']) # 整列保留0位小数 df['百分比'] = df['A1'].apply(lambda x:format(x,'.0%')) print(df) A1 A2 A3 A4 A5 百分比 0 0.207709 0.282517 0.241811 0.294174 0.383465 21% 1 0.463066 0.844255 0.409631 0.200746 0.157712 46% 2 0.764719 0.457153 0.181441 0.753263 0.576592 76% 3 0.747028 0.661603 0.014888 0.437514 0.163462 75% 4 0.670790 0.227655 0.953550 0.781417 0.820917 67% # 整列保留两位小数 df['百分比'] = df['A1'].apply(lambda x:format(x,'.2%')) print(df) A1 A2 A3 A4 A5 百分比 0 0.207709 0.282517 0.241811 0.294174 0.383465 20.77% 1 0.463066 0.844255 0.409631 0.200746 0.157712 46.31% 2 0.764719 0.457153 0.181441 0.753263 0.576592 76.47% 3 0.747028 0.661603 0.014888 0.437514 0.163462 74.70% 4 0.670790 0.227655 0.953550 0.781417 0.820917 67.08%
设置千位分隔符
由于业务需要,有时需要将数据格式化为带千位分隔符的数据。
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) data = [['Python数据分析','1月',49768889],['Python数据分析','2月',11777775],['Python数据分析','3月',13799990]] columns=['图书','月份','销量'] df = pd.DataFrame(data=data, columns=columns) # 设置千位分隔符 df['销量'] = df['销量'].apply(lambda x:format(int(x),',')) print(df) 图书 月份 销量 0 Python数据分析 1月 49,768,889 1 Python数据分析 2月 11,777,775 2 Python数据分析 3月 13,799,990
注: 设置千位分隔符后,对于程序来说,这些数据将不再是数值型,而是数字和逗号组成的字符串。
数据分组统计
对数据进行分组统计,主要使用 DataFrame 对象的 groupby 函数,其功能如下:
- 根据给定的条件将数据拆分成组
- 每个组都可以独立应用函数(如求和函数sum,求平均值函数mean等)
- 将结果合并到一个数据结构中
分组统计 groupby 函数
groupby 函数用于将数据按照一列或多列进行分组,一般与计算函数结合使用,实现数据的分组统计,语法如下:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False)
参数说明:
by: 映射、字典或Series对象、数组、标签或标签列表。如果by是一个函数,则对象索引的每个值都调用它;如果传递了一个字典或Series对象,则使用该字典或Series对象值来确定组;如果传递了数组ndarray,则按原样使用这些值来确定组 axis: axis=1表示行,axis=0表示列,默认值为0 level: 表示索引层级,默认None as_index: 布尔型,默认为True,返回以组标签为索引的对象 sort: 对组进行排序,布尔型,默认值值True group_keys: 布尔型,默认值为True,调用apply函数时,将分组的键添加到索引以标识字段 squeeze: 布尔型,默认为False,如果可能,减少返回类型的维度,否则返回一致类型 observed: 当以石斑鱼为分类时,才会使用该参数。如果参数为True,则仅显示分类石斑鱼的观测值;如果为False,则显示分类石斑鱼的所有值 返回值: DataFrameGroupBy,返回包含有关组的信息的 groupby对象
- 按照一列分组统计
import pandas as pd # 设置数据显示的列数和宽度 pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1000) # 解决数据输出时列名不对齐的问题 pd.set_option('display.unicode.east_asian_width', True) csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','7天点击量','订单预定']] # 分组统计求和 print(df1.groupby('一级分类').sum()) 7天点击量 订单预定 一级分类 数据库 186 15 移动开发 261 7 编程语言与程序设计 4280 192 网页制作/Web技术 345 15
- 按照多列分组统计
import pandas as pd # 设置数据显示的列数和宽度 pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1000) # 解决数据输出时列名不对齐的问题 pd.set_option('display.unicode.east_asian_width', True) csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','二级分类','7天点击量','订单预定']] # 分组统计求和 print(df1.groupby(['一级分类','二级分类']).sum())
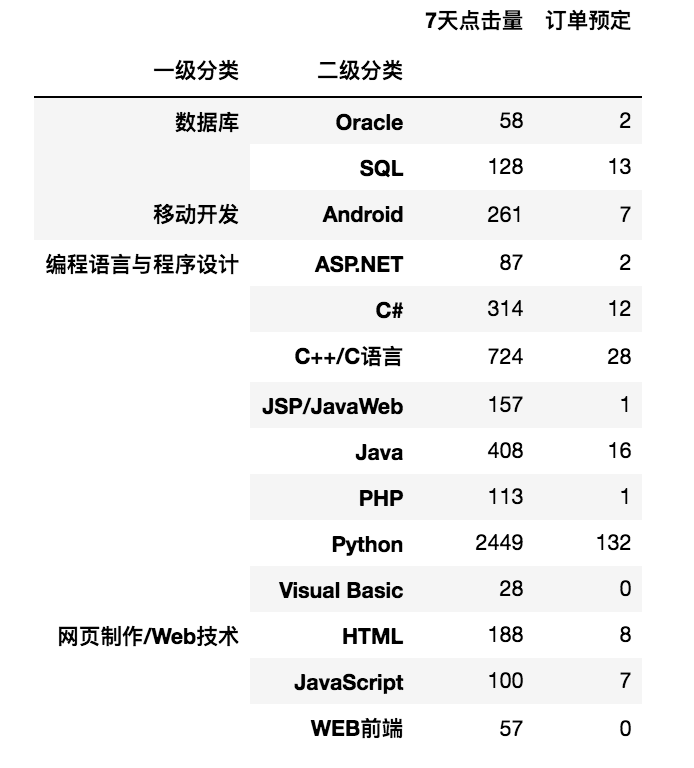
- 分组并按指定列进行数据计算
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','二级分类','7天点击量','订单预定']] # 首先按“二级分类”分组,然后取“7天点击量”列并对该列进行求和运算 print(df1.groupby(['二级分类'])['7天点击量'].sum()) 二级分类 ASP.NET 87 Android 261 C# 314 C++/C语言 724 HTML 188 JSP/JavaWeb 157 Java 408 JavaScript 100 Oracle 58 PHP 113 Python 2449 SQL 128 Visual Basic 28 WEB前端 57 Name: 7天点击量, dtype: int64
对分组数据进行迭代
- 迭代单列数据
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','7天点击量','订单预定']] for name,group in df1.groupby(['一级分类']): print(name) print(group) 数据库 一级分类 7天点击量 订单预定 25 数据库 58 2 27 数据库 128 13 移动开发 一级分类 7天点击量 订单预定 10 移动开发 85 4 19 移动开发 32 1 24 移动开发 85 2 28 移动开发 59 0 编程语言与程序设计 一级分类 7天点击量 订单预定 0 编程语言与程序设计 35 1 1 编程语言与程序设计 49 0 2 编程语言与程序设计 51 2 3 编程语言与程序设计 64 1 ... 32 编程语言与程序设计 28 0 网页制作/Web技术 一级分类 7天点击量 订单预定 7 网页制作/Web技术 100 7 14 网页制作/Web技术 188 8 17 网页制作/Web技术 57 0
- 迭代多列数据
如果 groupby 对多列进行分组,那么需要在 for 循环中指定多列。
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','二级分类','7天点击量','订单预定']] for (key1,key2),group in df1.groupby(['一级分类','二级分类']): print(key1,key2) print(group) 数据库 Oracle 一级分类 二级分类 7天点击量 订单预定 25 数据库 Oracle 58 2 数据库 SQL 一级分类 二级分类 7天点击量 订单预定 27 数据库 SQL 128 13 移动开发 Android 一级分类 二级分类 7天点击量 订单预定 10 移动开发 Android 85 4 19 移动开发 Android 32 1 24 移动开发 Android 85 2 28 移动开发 Android 59 0 编程语言与程序设计 ASP.NET 一级分类 二级分类 7天点击量 订单预定 0 编程语言与程序设计 ASP.NET 35 1 20 编程语言与程序设计 ASP.NET 52 1 编程语言与程序设计 C# 一级分类 二级分类 7天点击量 订单预定 5 编程语言与程序设计 C# 60 1 8 编程语言与程序设计 C# 122 3 26 编程语言与程序设计 C# 132 8 编程语言与程序设计 C++/C语言 一级分类 二级分类 7天点击量 订单预定 6 编程语言与程序设计 C++/C语言 227 11 9 编程语言与程序设计 C++/C语言 111 5 11 编程语言与程序设计 C++/C语言 165 5 18 编程语言与程序设计 C++/C语言 149 4 29 编程语言与程序设计 C++/C语言 27 2 31 编程语言与程序设计 C++/C语言 45 1 编程语言与程序设计 JSP/JavaWeb 一级分类 二级分类 7天点击量 订单预定 4 编程语言与程序设计 JSP/JavaWeb 26 0 12 编程语言与程序设计 JSP/JavaWeb 131 1 编程语言与程序设计 Java 一级分类 二级分类 7天点击量 订单预定 2 编程语言与程序设计 Java 51 2 13 编程语言与程序设计 Java 149 10 16 编程语言与程序设计 Java 125 1 23 编程语言与程序设计 Java 83 3 编程语言与程序设计 PHP 一级分类 二级分类 7天点击量 订单预定 1 编程语言与程序设计 PHP 49 0 3 编程语言与程序设计 PHP 64 1 编程语言与程序设计 Python 一级分类 二级分类 7天点击量 订单预定 15 编程语言与程序设计 Python 1139 79 21 编程语言与程序设计 Python 597 25 22 编程语言与程序设计 Python 474 15 30 编程语言与程序设计 Python 239 13 编程语言与程序设计 Visual Basic 一级分类 二级分类 7天点击量 订单预定 32 编程语言与程序设计 Visual Basic 28 0 网页制作/Web技术 HTML 一级分类 二级分类 7天点击量 订单预定 14 网页制作/Web技术 HTML 188 8 网页制作/Web技术 JavaScript 一级分类 二级分类 7天点击量 订单预定 7 网页制作/Web技术 JavaScript 100 7 网页制作/Web技术 WEB前端 一级分类 二级分类 7天点击量 订单预定 17 网页制作/Web技术 WEB前端 57 0
对分组的某列或多列使用聚合函数
Python 中也可以实现像 SQL 中的分组聚合运算操作,主要通过 groupby 函数与 agg 函数实现。
- 对分组统计结果使用聚合函数
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','二级分类','7天点击量','订单预定']] # 按“一级分类”分组统计,“7天点击量”和“订单预定”的平均值总和 print(df1.groupby(['一级分类']).agg(['mean','sum']))
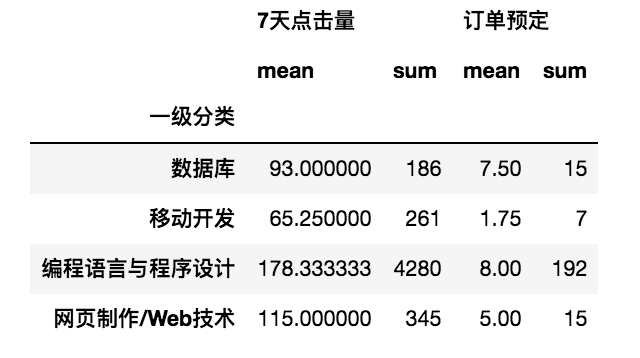
- 针对不同的列使用不同的聚合函数
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/15/JD.csv' df = pd.read_csv(csv_file, encoding='gbk') df1 = df[['一级分类','二级分类','7天点击量','订单预定']] # 按“一级分类”分组统计,“7天点击量”的平均值总和以及“订单预定”总和 print(df1.groupby(['一级分类']).agg({'7天点击量':['mean','sum'],'订单预定':['sum']}))
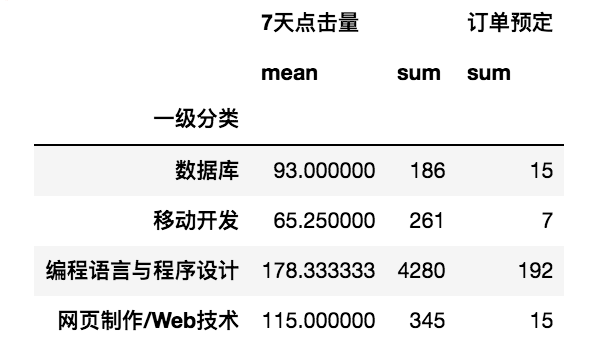
- 通过自定义函数实现分组统计
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/22/1月.xlsx' df = pd.read_excel(excel_file) # value_counts函数用于Series对象中的每个值进行计数并且排序 max1= lambda x:x.value_counts(dropna=False).index[0] # 使用__name__方法修改lambda函数名称 max1.__name__ = "购买次数最多" df1 = df.agg({'宝贝标题':[max1], '数量':['sum','mean'], '买家实际支付金额':['sum','mean']}) print(df1) 宝贝标题 数量 买家实际支付金额 mean NaN 1.06 50.5712 sum NaN 53.00 2528.5600 购买次数最多 零基础学Python NaN NaN
从运行结果得知: 《零基础学Python》是用户购买次数最多的产品。
通过字典和 Series 进行分组统计
- 通过字典进行分组统计
首先创建字典建立对应关系,然后将字典传递给 groupby 函数,从而实现数据分组统计。
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/23/JD.csv' df = pd.read_csv(csv_file,encoding='gbk') df = df.set_index(['商品名称']) dict1 = {'北京出库销量':'北上广','上海出库销量':'北上广','广州出库销量':'北上广', '成都出库销量':'成都','武汉出库销量':'武汉','西安出库销量':'西安'} df1 = df.groupby(dict1,axis=1).sum() print(df1)
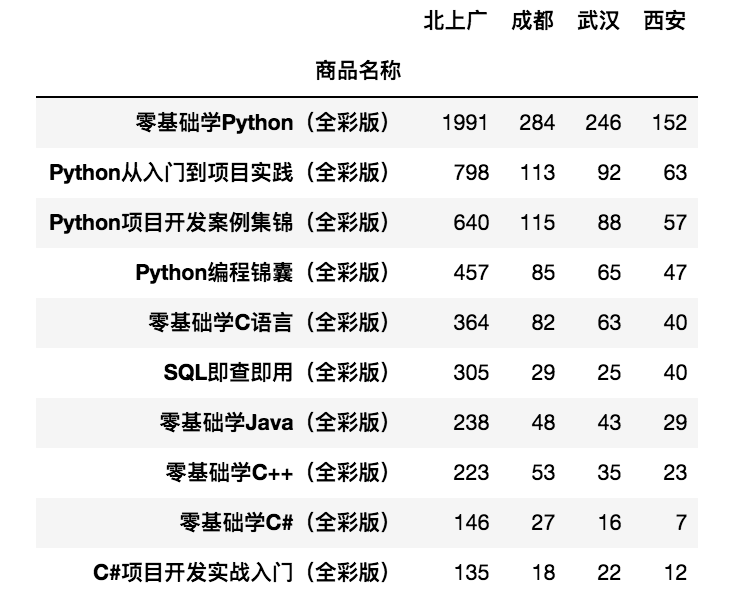
- 通过 Series 对象进行分组统计
通过 Series 对象进行分组统计时,它与字典的方法类似。
import pandas as pd csv_file = r'../../../DataAnalysis/Code/04/23/JD.csv' df = pd.read_csv(csv_file,encoding='gbk') df = df.set_index(['商品名称']) data = {'北京出库销量':'北上广','上海出库销量':'北上广','广州出库销量':'北上广', '成都出库销量':'成都','武汉出库销量':'武汉','西安出库销量':'西安'} s1 = pd.Series(data) df1 = df.groupby(s1,axis=1).sum() print(df1)
数据移位
什么是数据移位?例如,数据分析时需要上一条数据怎么办?当然是移动至上一条,从而得到该条数据,这就是数据移位。在 Pandas 中,使用 shift 方法可以获得上一条数据,该方法将返回向下移位后的结果,从而得到上一条数据。语法如下:
DataFrame.shift(periods=1, freq=None, axis=0)
参数说明:
periods: 表示移动的幅度,可以是正数;也可以是负数,默认值为1,1表示移动一次,注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就被赋值为NaN freq: 可选参数,默认值为None,只适用于时间序列,如果这个参数存着,那么会按照参数值来移动时间索引,而数据值不会发生变化 axis: axis=1表示行,axis=0表示列,默认值为0
- 使用
shift方法统计学生每周英语测试成绩的升降情况
import pandas as pd data = [110,105,99,120,115] index = [1,2,3,4,5] columns = ['英语'] df = pd.DataFrame(data=data,index=index,columns=columns) df['升降'] = df['英语'] - df['英语'].shift(1) print(df) 英语 升降 1 110 NaN 2 105 -5.0 3 99 -6.0 4 120 21.0 5 115 -5.0
从运行结果可知: 第2次比第1次下降了5分;第3次比第2次下降了6分;第4次比第3次提升了21分。
数据转换
数据转换一般包括一列数据转换为多列数据、行列转换、DataFrame转换为字典、列表和元祖等。
一列数据转换为多列数据
Pandas 的 DataFrame 对象中的 str.split 内置方法可以实现分隔字符串,语法如下:
obj.str.split(pat=None, n=-1, expand=False)
参数说明:
pat: 字符串、符合或正则表达式,表示字符串分割的依据,默认以空格分隔字符串 n: 整型,分割次数,默认值是-1。0或-1都将返回所有拆分的字符串 expand: 布尔型,分割后的结果是否转换为 DataFrame,默认值为False 返回值: 索引、DataFrame或多重索引
- 分割 “收货地址” 数据中的 “省、市、区”
import pandas as pd # 设置数据显示的列数和宽度 pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1000) # 解决数据输出时列名不对齐的问题 pd.set_option('display.unicode.east_asian_width', True) excel_file = r'../../../DataAnalysis/Code/04/26/mrbooks.xls' # 导入Excel文件并指定列数据 df = pd.read_excel(excel_file,usecols=['买家会员名','收货地址']) # 使用str.split方法分割“收货地址” s1 = df['收货地址'].str.split(' ',expand=True) df['省'] = s1[0] df['市'] = s1[1] df['区/县'] = s1[2] print(df.tail(10))

- 通过 join 方法与 split 方法结合,以逗号 “,” 分割
import pandas as pd # 设置数据显示的列数和宽度 pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1000) # 解决数据输出时列名不对齐的问题 pd.set_option('display.unicode.east_asian_width', True) excel_file = r'../../../DataAnalysis/Code/04/26/mrbooks.xls' # 导入Excel文件并指定列数据 df = pd.read_excel(excel_file,usecols=['买家会员名','宝贝标题']) df = df.join(df['宝贝标题'].str.split(',',3,expand=True)) print(df.head(5))

- 对元祖数据进行分割
import pandas as pd df = pd.DataFrame({'a':[1,2,3,4,5], 'b':[(1,2),(3,4),(5,6),(7,8),(9,10)]}) # 使用apply函数对元祖进行分割 df[['b1','b2']] = df['b'].apply(pd.Series) print(df) a b b1 b2 0 1 (1, 2) 1 2 1 2 (3, 4) 3 4 2 3 (5, 6) 5 6 3 4 (7, 8) 7 8 4 5 (9, 10) 9 10 # 使用join方法结合apply函数对元祖进行分割 df = df.join(df['b'].apply(pd.Series)) print(df) a b 0 1 0 1 (1, 2) 1 2 1 2 (3, 4) 3 4 2 3 (5, 6) 5 6 3 4 (7, 8) 7 8 4 5 (9, 10) 9 10
行列转换
在 Pandas 处理数据的过程中,有时需要对数据进行行列转换或重排,这时主要使用 stack 方法、unstack 方法和 pivot 方法。
- stack 方法
stack 方法用于将原来的列索引转换成最内层的行索引,语法如下:
DataFrame.stack(level=-1, dropna=True)
参数说明:
level: 索引层级,定义为一个标签或索引或标签列表,默认值为-1 dropna: 布尔型,默认值为True 返回值: DataFrame对象或Series对象
使用示例:
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/29/grade.xls' df = pd.read_excel(excel_file) # 设置2级索引“班级”和“序号” df = df.set_index(['班级','序号']) df = df.stack() print(df.head(10)) 班级 序号 1班 1 姓名 王*亮 得分 84 排名 11 2 姓名 杨** 得分 82 排名 17 3 姓名 王*彬 得分 78 排名 37 2班 4 姓名 赛*琪 dtype: object
- unstack 方法
unstack 方法与 stack 方法相反,它是 stack 方法的逆操作,即将最内层的行索引转换成列索引,语法如下:
DataFrame.unstack(level=-1, fill_value=None)
参数说明:
level: 索引层级,定义为一个标签或索引或标签列表,默认值为-1 fill_value: 整型、字符串或字典,如果unstack方法产生丢失值,则用这个值替换NaN 返回值: 返回DataFrame对象或Series对象
使用示例:
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/29/grade.xls' df = pd.read_excel(excel_file,sheet_name='英语2') # 设置多级索引 df = df.set_index(['班级','序号','Unnamed: 2']) df.unstack()
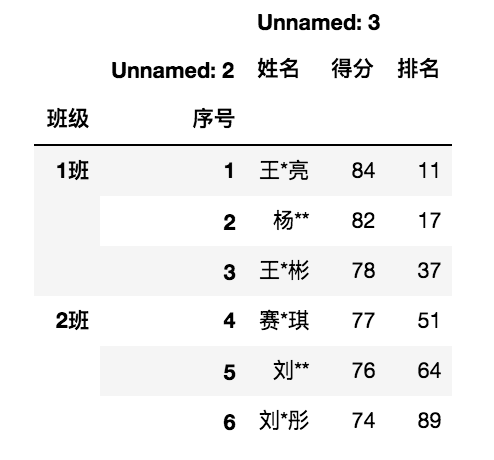
- pivot 方法
pivot 方法针对列的值,即指定某列的值作为行索引,指定某列的值作为列索引,然后再指定哪些列作为索引对应的值。unstack 方法针对索引进行操作;pivot 方法针对值进行操作。语法如下:
DataFrame.pivot(index=None, columns=None, values=None)
参数说明:
index: 字符串或对象,可选参数。列用于创建新DataFrame数据的索引,如果没有,则使用现有索引 columns: 字符串或对象,列来创建新DataFrame数据的列 values: 列用于填充新DataFrame数据的值,如果未指定,则将使用所有剩余的列,结果将具有分层索引列 返回值: 返回DataFrame对象
使用示例:
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/29/grade.xls' df = pd.read_excel(excel_file,sheet_name='英语3') print(df.pivot(index='序号',columns='班级',values='得分')) 班级 1班 2班 3班 4班 5班 序号 1 84 77 72 72 70 2 82 76 72 72 68 3 78 74 72 70 68
DataFrame 的转换
- DataFrame 转换为字典
将 DataFrame 转换为字典主要使用 DataFrame 对象中的 to_dict 方法,以索引作为字典的键,以列作为字典的值。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/32/mrbooks.xls' df = pd.read_excel(excel_file) df1 = df.groupby(['宝贝标题'])['宝贝总数量'].sum().head() dict1 = df1.to_dict() for i,j in dict1.items(): print(i,':\t',j) ASP.NET项目开发实战入门全彩版 : 32 ASP.NET项目开发实战入门全彩版,ASP.NET全能速查宝典 : 2 Android学习黄金组合套装 : 4 Android项目开发实战入门 : 1 C#+ASP.NET项目开发实战入门全彩版 : 1
- DataFrame 转换为列表
将 DataFrame 对象转换为列表时,主要使用 DataFrame 的 tolist 方法。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/32/mrbooks.xls' df = pd.read_excel(excel_file) df1 = df[['买家会员名']].head() list1 = df1['买家会员名'].values.tolist() for i in list1: print(i) mr00001 mr00003 mr00004 mr00002 mr00005
- DataFrame 转换为元祖
将 DataFrame 对象转换为元祖时,首先通过循环语句按行读取 DataFrame 数据,然后使用元祖函数 tuple 将其转换为元祖。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/34/fl4.xls' df = pd.read_excel(excel_file) df1 = df[['label1','label2']].head() tuple1 = [tuple(x) for x in df1.values] for t in tuple1: print(t) ('超巨星', '暗夜比夜星') ('黑矮星', '暗夜比夜星') ('灭霸', '暗夜比夜星') ('亡刃将军', '暗夜比夜星') ('乌木喉', '暗夜比夜星')
Excel 转换为 HTML 网页格式
首先使用 read_excel 方法导入 Excel 文件,然后使用 to_html 方法将 DataFrame 数据导出为 HTML 格式,这样便实现了 Excel 转换为 HTML 格式的功能。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/35/mrbooks.xls' df = pd.read_excel(excel_file) df.to_html('mrbooks.html',header=True,index=False)
数据合并
DataFrame 数据合并主要使用 Merge 方法、Concat 方法。
使用 Merge 方法
Pandas 模块的 Merge 方法是按照两个 DataFrame 对象列名相同的列进行连接合并,语法如下:
pandas.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=FAlse, sort_False, sufixes=('_x','_y'), copy=True, indicator=False, validate=None)
参数说明:
right: 合并对象,DataFrame对象或Series对象 how: 合并类型,参数值可以是left(左合并)、right(右合并)、outer(外部合并)或inner(内部合并),默认值为inner - left: 只使用来自左数据集的键,类似于SQL左外连接,保留键的顺序 - right: 只使用来自右数据集的键,类似于SQL右外连接,保留键的顺序 - outer: 使用来自两个数据集的键,类似于SQL外连接,按字典顺序对键进行排序 - inner: 使用来自两个数据集的键的交集,类似于SQL内连接,保持左键的顺序 on: 标签、列表或数组,默认值为None。DataFrame对象连接的列或索引级名称;也可以是左数据集长度的数组或数组列表 left_on: 标签、列表或数组,默认值为None。要连接的左数据集的列或索引级名称,也可以是左数据集长度的数组或数组列表 right_on: 标签、列表或数组,默认值为None。要连接的右数据集的列或索引级名称,也可以是右数据集长度的数组或数组列表 left_index: 布尔型,默认值为False。使用左数据集的索引作为连接键,如果是多重索引,则其它数据中的键数(索引或列数)必须匹配索引级别数 right_index: 布尔型,默认值为False。使用右数据集的索引作为连接键 sort: 布尔型,默认值为False。在合并结果中按字典顺序对连接键进行排序,如果为False,则连接键的顺序取决于连接类型how参数 suffixes: 元祖类型,默认值为('_x','_y')。当左侧数据集和右侧数据集的列名相同时,数据合并后列名将带上“_x”和“_y”后缀 copy: 是否复制数据,默认值为True。如果为False,则不复制数据 indicator: 布尔型或字符串,默认值为False。如果值为True,则添加一个列以输出名“_Merge”的DataFrame对象,其中包含每一行的信息;如果是字符串,将向输出的DataFrame对象中添加包含每一行信息的列,并将列命名为字符型的值 validate: 字符串,检查合并数据是否为指定类型。可选参数 - one_to_one或“1:1”: 检查合并键在左右数据集中是否都是唯一的 - one_to_many或“1:m”: 检查合并键在左数据集中是否唯一 - many_to_one或“m:1”: 检查合并键在右数据集中是否唯一 - many_to_many或“m:m”: 允许,但不检查 返回值: 返回DataFrame对象,两个合并对象的数据集
- 常规合并
import pandas as pd df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '语文':[110,105,109], '数学':[105,88,120], '英语':[99,115,130]}) df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '体育':[34.5,39.7,38]}) df = pd.merge(df1,df2,on='编号') print(df) 编号 语文 数学 英语 体育 0 mr001 110 105 99 34.5 1 mr002 105 88 115 39.7 2 mr003 109 120 130 38.0 # 通过索引列合并数据 df = pd.merge(df1,df2,left_index=True,right_index=True) print(df) 编号_x 语文 数学 英语 编号_y 体育 0 mr001 110 105 99 mr001 34.5 1 mr002 105 88 115 mr002 39.7 2 mr003 109 120 130 mr003 38.0
- 对合并数据去重
从上面的运行结果可知: 数据中存在重复列(如编号),如果不想要重复列,可以设置按指定列和列索引合并数据。
import pandas as pd df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '语文':[110,105,109], '数学':[105,88,120], '英语':[99,115,130]}) df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '体育':[34.5,39.7,38]}) # 按指定列和列索引合并数据 df = pd.merge(df1,df2,on='编号',left_index=True,right_index=True) print(df) 编号 语文 数学 英语 体育 0 mr001 110 105 99 34.5 1 mr002 105 88 115 39.7 2 mr003 109 120 130 38.0
还可以通过 how 参数解决这一问题。例如,设置该参数为 left,就是让 df1 保留所有的行列数据,df2 则根据 df1 的行列进行补全。
import pandas as pd df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '语文':[110,105,109], '数学':[105,88,120], '英语':[99,115,130]}) df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '体育':[34.5,39.7,38]}) # 通过参数how合并数据 df = pd.merge(df1,df2,on='编号',how='left') print(df) 编号 语文 数学 英语 体育 0 mr001 110 105 99 34.5 1 mr002 105 88 115 39.7 2 mr003 109 120 130 38.0
- 多对一的数据合并
多对一是指两个数据集(df1、df2)的共有列中的数据不是一对一的关系,例如 df1 中的 “编号” 列是唯一的,而 df2 中的 “编号” 列中有重复的内容,类似这种就是多对一的关系。
import pandas as pd df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'], '姓名':['小明','小红','小芳']}) df2 = pd.DataFrame({'编号':['mr001','mr001','mr003'], '语文':[110,105,109], '数学':[105,88,120], '英语':[99,115,130], '时间':['1月','2月','1月']}) df = pd.merge(df1,df2,on='编号') print(df) 编号 姓名 语文 数学 英语 时间 0 mr001 小明 110 105 99 1月 1 mr001 小明 105 88 115 2月 2 mr003 小芳 109 120 130 1月
- 多对多的数据合并
多对多是指两个数据集(df1、df2)的共有列中的数据不全是一对一的关系,都包含了重复数据,例如 “编号” 列。
import pandas as pd df1 = pd.DataFrame({'编号':['mr001','mr002','mr003','mr001','mr001'], '体育':[34.5,39.7,38,33,35]}) df2 = pd.DataFrame({'编号':['mr001','mr002','mr003','mr003','mr003'], '语文':[110,105,109,110,108], '数学':[105,88,120,123,119], '英语':[99,115,130,109,128]}) df = pd.merge(df1,df2) print(df) 编号 体育 语文 数学 英语 0 mr001 34.5 110 105 99 1 mr001 33.0 110 105 99 2 mr001 35.0 110 105 99 3 mr002 39.7 105 88 115 4 mr003 38.0 109 120 130 5 mr003 38.0 110 123 109 6 mr003 38.0 108 119 128
使用 Concat 方法
Concat 方法可以根据不同的方式将数据合并,语法如下:
pandas.concat(objs, axis=0, join='outer', ignore_index: bool=False, keys=None, levels=None, names=None, verify_integrity: bool=False, copy: bool=True)
参数说明:
obj: Series、DataFrame或Panel对象的序列或映射。如果传递一个字典,则排序的键将用作键参数 axis: axis=1表示行;axis=0表示列,默认值为0 join: 值为inner或outer,处理其它轴上的索引方式。默认值为outer ignore_index: 布尔值,默认值为False。如果为True,请不要使用并置轴上的索引值,结果轴被标记为0,1,...,n-1。如果要连接并置轴中没有意义的索引信息的对象,这将非常有用。注意,其它轴上的索引值在连接中仍然会被使用 keys: 序列,默认值为None。用于构建MultiIndex参数的特定级别(唯一值)。否则,它们将从键推断 names: list列表,默认值为None。结果层次索引中的级别的名称 verify_integrity: 布尔值,默认值为False。检查新连接的轴是否包含重复项 copy: 是否复制数据,默认值为True。如果为False,则不复制数据
- 相同字段的表首尾相接
表结构相同的数据将直接合并,即表首尾相接。例如,表 df1、df2、df3 的结构相同。
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'A':['mrA03','mrA04','mrA05','mrA06'], 'B':['mrB03','mrB04','mrB05','mrB06'], 'C':['mrC03','mrC04','mrC05','mrC06'], 'D':['mrD03','mrD04','mrD05','mrD06']}) df3 = pd.DataFrame({'A':['mrA07','mrA08','mrA09','mrA10'], 'B':['mrB07','mrB08','mrB09','mrB10'], 'C':['mrC07','mrC08','mrC09','mrC10'], 'D':['mrD07','mrD08','mrD09','mrD10']}) # 直接合并 print(pd.concat([df1,df2,df3])) A B C D 0 mrA01 mrB01 mrC01 mrD01 1 mrA02 mrB02 mrC02 mrD02 0 mrA03 mrB03 mrC03 mrD03 1 mrA04 mrB04 mrC04 mrD04 2 mrA05 mrB05 mrC05 mrD05 3 mrA06 mrB06 mrC06 mrD06 0 mrA07 mrB07 mrC07 mrD07 1 mrA08 mrB08 mrC08 mrD08 2 mrA09 mrB09 mrC09 mrD09 3 mrA10 mrB10 mrC10 mrD10
# 合并数据时使用keys参数,标记源数据来自哪张表 print(pd.concat([df1,df2,df3],keys=['1月','2月','3月']))

- 横向表合并(行对齐)
当合并的数据列名称不一致时,可以设置参数 axis=1,Concat 方法将按行对齐,然后将不同列名的两组数据进行合并,缺失的数据用 NaN 填充。
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'D':['mrD01','mrD02','mrD03','mrD04','mrD05'], 'E':['mrE01','mrE02','mrE03','mrE04','mrE05'], 'F':['mrF01','mrF02','mrF03','mrF04','mrF05']}) # 按行对齐 print(pd.concat([df1,df2],axis=1)) A B C D D E F 0 mrA01 mrB01 mrC01 mrD01 mrD01 mrE01 mrF01 1 mrA02 mrB02 mrC02 mrD02 mrD02 mrE02 mrF02 2 NaN NaN NaN NaN mrD03 mrE03 mrF03 3 NaN NaN NaN NaN mrD04 mrE04 mrF04 4 NaN NaN NaN NaN mrD05 mrE05 mrF05
- 交叉合并
想要交叉合并,需要在代码中加上 join 参数,如果值为 “inner”,结果是两表的交集;如果值为 “outer”,结果是两表的并集。
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'D':['mrD01','mrD02','mrD03','mrD04','mrD05'], 'E':['mrE01','mrE02','mrE03','mrE04','mrE05'], 'F':['mrF01','mrF02','mrF03','mrF04','mrF05']}) # 按行对齐,取交集 print(pd.concat([df1,df2],axis=1,join='inner')) A B C D D E F 0 mrA01 mrB01 mrC01 mrD01 mrD01 mrE01 mrF01 1 mrA02 mrB02 mrC02 mrD02 mrD02 mrE02 mrF02 # 按行对齐,取并集 print(pd.concat([df1,df2],axis=1,join='outer')) A B C D D E F 0 mrA01 mrB01 mrC01 mrD01 mrD01 mrE01 mrF01 1 mrA02 mrB02 mrC02 mrD02 mrD02 mrE02 mrF02 2 NaN NaN NaN NaN mrD03 mrE03 mrF03 3 NaN NaN NaN NaN mrD04 mrE04 mrF04 4 NaN NaN NaN NaN mrD05 mrE05 mrF05
数据导出
- 导出为 xlsx 文件
导出数据为 Excel 文件,主要使用 DataFrame 对象的 to_excel 方法,语法如下:
DataFrame.to_excel(excel_write, sheet_name=’Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
参数说明:
excel_write: 字符串或ExcelWriter对象 sheet_name: 字符串,默认值为“Sheet1”,包含DataFrame数据的表的名称 na_rep: 字符串,默认值为'',缺失数据的表示方式 float_format: 字符串,默认值为None,格式化浮点数的字符串 columns: 序列,可选参数,要编辑的列 header: 布尔型或字符串列表,默认值为True。列名称,如果给定字符串列表,则表示它是列名称的别名 index: 布尔型,默认值为True,行名(索引) index_label: 字符串或序列,默认值为None。如果需要,可以使用索引列的列标签。如果没有给出,标题和索引为True,则使用索引名称。如果数据文件使用多索引,则需使用序列 startrow: 指定从哪一行开始写入数据 startcol: 指定从哪一列开始写入数据 engine: 字符串,默认值为None。使用写引擎,也可以通过io.excel.xlsx.writer、io.excel.xls.writer和io.excel.xlsm.writer方法进行设置 merge_cells: 布尔型,默认值为True inf_rep: 字符串,默认值为“inf”,表示无穷大 freeze_panes: 整数的元祖,长度为2,默认值为None。指定要冻结的行列
使用示例:
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'D':['mrD01','mrD02','mrD03','mrD04','mrD05'], 'E':['mrE01','mrE02','mrE03','mrE04','mrE05'], 'F':['mrF01','mrF02','mrF03','mrF04','mrF05']}) # 按行对齐,取并集 df = pd.concat([df1,df2],axis=1,join='outer') # 导出为Excel文件 df.to_excel('merge.xlsx') # 导出为Excel文件,并指定Sheet页名称 df.to_excel('concat.xlsx',sheet_name='df')
- 导出为 csv 文件
导出数据为 csv 问,主要使用 DataFrame 对象中的 to_csv 方法,语法如下:
DataFrame.to_csv(path_or_buf, sep, na_rep, float_format, columns, header, index, index_label, mode, encoding, line_terminator, quoting, quotechar, doublequote, escapechar, chunksize, tupleize_cols, date_format)
参数说明:
path_or_buf: 要保存的路径及文件名 sep: 分隔符,默认值为 “,” na_rep: 指定空值的输出方式,默认为空字符串 float_format: 浮点数的输出格式,要用引号括起来 columns: 指定要输出的列,用列名、列表表示,默认值为None header: 是否输出列名,默认值为True index: 是否输出索引,默认值为True index_label: 索引列的列名,默认值为None encoding: 编码方式,默认值为“utf-8” line_terminator: 换行符,默认值为“\n” quoting: 导出csv文件是否用引号,默认值为0,表示不加引号;如果值为1,则每个字段都会加上引号,数值也会被当做字符串看待 quotechar: 引用字符,当quoting=1时可以指定引号字符为双引号或单引号 chunksize: 一次写入csv文件的行数,当DataFrame对象数据特别大时需要分批写入 date_format: 日期输出格式
使用示例:
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'D':['mrD01','mrD02','mrD03','mrD04','mrD05'], 'E':['mrE01','mrE02','mrE03','mrE04','mrE05'], 'F':['mrF01','mrF02','mrF03','mrF04','mrF05']}) # 按行对齐,取并集 df = pd.concat([df1,df2],axis=1,join='outer') # 导出为csv文件 df.to_csv('merge.csv')
下面为 to_csv 方法的常用功能,举例如下,df 为 DataFrame 对象。
# 相对位置,保存在程序所在路径下 df.to_csv(Result.csv) # 绝对位置 df.to_csv('d:\Result.csv') # 分隔符,使用问号“?”分隔符分隔需要保存的数据 df.to_csv('Result.csv',sep='?') # 替换空值,缺失值保存为NA df.to_csv('Result.csv',na_rep='NA') # 格式化数据,保留两位小数 df.to_csv('Result.csv',float_format='%.2f') # 保留某列数据,保存索引列和name列 df.to_csv('Result.csv',columns=['name']) # 是否保留列名,不保留列名 df.to_csv('Result.csv',header=0) # 是否保留行索引,不保留行索引 df.to_csv('Result.csv',index=0)
- 导出到多个 Sheet 页中
导出到多个 Sheet 页中,应首先使用 pd.ExcelWrite 方法打开一个 Excel 文件,然后再使用 to_csv 方法导出至指定的 Sheet 页中。
import pandas as pd df1 = pd.DataFrame({'A':['mrA01','mrA02'], 'B':['mrB01','mrB02'], 'C':['mrC01','mrC02'], 'D':['mrD01','mrD02']}) df2 = pd.DataFrame({'D':['mrD01','mrD02','mrD03','mrD04','mrD05'], 'E':['mrE01','mrE02','mrE03','mrE04','mrE05'], 'F':['mrF01','mrF02','mrF03','mrF04','mrF05']}) # 按行对齐,取并集 df = pd.concat([df1,df2],axis=1,join='outer') # 打开一个Excel文件(文件不存在则会新建) work = pd.ExcelWriter('ExcelWriter.xlsx') df.to_excel(work,sheet_name='df1') df['A'].to_excel(work,sheet_name='df2') work.save()
日期数据处理
- DataFrame 对象的日期数据转换
在 Pandas 中提供了 to_datetime 方法可以用来批量进行日期数据转换,对于处理大数据非常的实用和方便,它可以将日期数据转换成所需的各种格式。例如,将 2/14/20 转换为日期格式——2020-02-14。语法如下:
pandas.to_datetime(arg, errors='ignore', dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=False)
参数说明:
arg: 字符串、日期时间、字符串数组 errors: 值为ignore、raise或coerce,默认值ignore忽略错误。具体说明如下: - ignore: 无效的解析将返回原值 - raise: 无效的解析将引发异常 - coerce: 无效的解析将被设置NaT,即无法转换为日期的数据转换为NaT dayfirst: 第一天,布尔型,默认值为False。如果为True,解析日期为第一天 utc: 默认值为None,返回utc即协调世界时间 box: 布尔值,默认值为True。如果为True,返回DatatimeIndex;如果为False,返回值的ndarray format: 格式化显示时间的格式。字符串,默认值为None exact: 布尔值,默认值为True。如果为True,则要求格式完全匹配;如果为False,则允许格式与目标字符串中的任何位置匹配 unit: 默认值为None。参数的单位(D、s、ms、ns)表示时间的单位,它是整数/浮点数 infer_datetime_format: 默认值为False。如果没有格式,则尝试根据第一个日期字符串推断格式 origin: 默认值为unix。定义参考日期,数值将被解析为单位数 cache: 默认值为False。如果为True,则使用唯一、转换日期的缓存应用日期进行转换。在解析重复日期字符串,特别是带有时区偏移的字符串时,可能会产生明显的加速。只有在至少有50个值时才使用缓存。越界值的存着将使缓存不可用,并可能减慢解析速度 返回值: 日期时间
使用示例:
# 将各种日期字符串转换为指定的日期格式 import pandas as pd pd.set_option('display.unicode.east_asian_width', True) df = pd.DataFrame({'原日期':['14-Feb-20','02/14/20','2020.02.14','2020/02/14','20200214']}) df['转换后的日期'] = pd.to_datetime(df['原日期']) print(df) 原日期 转换后的日期 0 14-Feb-20 2020-02-14 1 02/14/20 2020-02-14 2 2020.02.14 2020-02-14 3 2020/02/14 2020-02-14 4 20200214 2020-02-14 # 将一组数据合并为日期数据 # 将一组数据合并为日期数据 import pandas as pd pd.set_option('display.unicode.east_asian_width', True) df = pd.DataFrame({'year' :[2018,2019,2020], 'month' :[1,3,2], 'day' :[5,9,17], 'hour' :[13,8,2], 'minute':[23,12,14], 'second':[2,4,0]}) df['组合后的日期'] = pd.to_datetime(df) print(df) year month day hour minute second 组合后的日期 0 2018 1 5 13 23 2 2018-01-05 13:23:02 1 2019 3 9 8 12 4 2019-03-09 08:12:04 2 2020 2 17 2 14 0 2020-02-17 02:14:00
- dt 对象的使用
dt 对象是 Series 对象中用于获取日期属性的访问器对象,通过它可以获取日期中的年、月、日、星期数、季度等,还可以判断日期是否处在年底。语法如下:
Series.dt()
参数说明:
返回值: 返回与原始系列相同的索引系列。如果Series对象不包含日期值,则引发错误
dt 对象提供了 year、month、day、dayofweek、dayofyear、is_leap_year、quarter、weekday_name 等属性和方法。例如,year 可以获取 “年”、month 可以获取 “月”、quarter 可以直接获取每个日期分别是第几个季度。
使用示例:
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) df = pd.DataFrame({'原日期':['2019.01.05','2019.02.15','2019.03.25','2019.06.25','2019.09.15','2019.12.31']}) df['日期'] = pd.to_datetime(df['原日期']) # 获取年、月、日 df['年'],df['月'],df['日'] = df['日期'].dt.year,df['日期'].dt.month,df['日期'].dt.day # 从日期判断所处的星期数 df['星期几'] = df['日期'].dt.day_name() # 从日期判断所处的季度 df['季度'] = df['日期'].dt.quarter # 从日期判断是否为年末 df['是否年末'] = df['日期'].dt.is_year_end print(df)
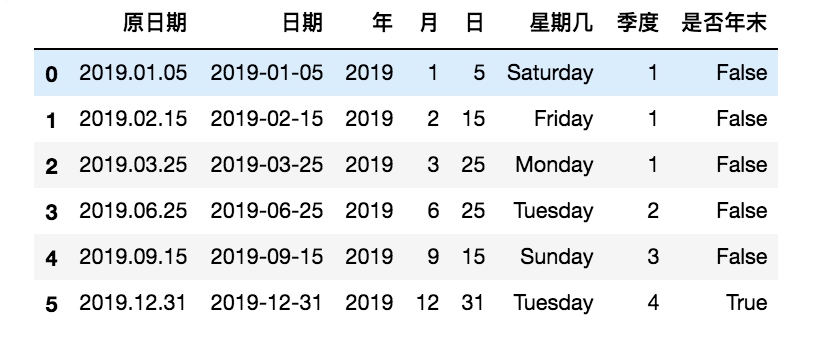
- 获取日期区间的数据
获取日期区间的数据的方法是直接在 DataFrame 对象中输入日期或日期区间,但前提是必须设置日期为索引。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/47/mingribooks.xls' df = pd.read_excel(excel_file, usecols=['订单付款时间','买家会员名','联系手机','买家实际支付金额']) df = df.sort_values(by=['订单付款时间']) # 设置日期为索引 df = df.set_index('订单付款时间') # 获取某年的数据 print(df['2018']) # 获取多年的数据 print(df['2017':'2018']) # 获取某月的数据 print(df['2018-07']) # 获取多月的数据 print(df['2018-07':'2018-08']) # 获取某天的数据 print(df['2018-05-06']) # 获取多天的数据 print(df['2018-05-06':'2018-05-12'])
- 按不同时期统计数据
按不同时期统计数据主要通过 DataFrame 对象中的 resample 方法结合数据计算函数实现。resample 方法主要应用于时间序列的频率转换和重采样,它可以从日期中获取年、月、日、星期、季度等,结合数据计算函数可以实现年、月、日、星期或季度等不同时期来统计数据。resample 函数要求索引必须为日期类型。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/47/mingribooks.xls' df = pd.read_excel(excel_file, usecols=['订单付款时间','买家会员名','联系手机','买家实际支付金额']) df = df.sort_values(by=['订单付款时间']) # 设置日期为索引 df = df.set_index('订单付款时间') # 将数据的索引转换为datetime类型 df.index = pd.to_datetime(df.index) # 按年统计数据 df = df.resample('AS').sum() # 按季度统计数据 df = df.resample('Q').sum() # 按月度统计数据 df = df.resample('M').sum() # 按星期统计数据 df = df.resample('W').sum() # # 按天统计数据 df = df.resample('D').sum() print(df) 买家实际支付金额 订单付款时间 2018-04-01 111219.8
- 按不同时期显示数据
DataFrame 对象中的 period 方法可以将时间戳转换为时期,从而实现按不同时期显示数据,前提是日期必须设置为索引。语法如下:
DataFrame.period(freq=None, axis=0, copy=True)
参数说明:
freq: 字符串,周期索引的频率,默认值为None axis: 行列索引,0为行索引,1为列索引,默认值为0 copy: 是否复制数据,默认值为True;如果为False,则不会复制数据 返回值: 带周期索引的时间序列
使用示例:
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/47/mingribooks.xls' df = pd.read_excel(excel_file, usecols=['订单付款时间','买家会员名','联系手机','买家实际支付金额']) df = df.sort_values(by=['订单付款时间']) # 设置日期为索引 df = df.set_index('订单付款时间') # 按“年”显示数据 print(df.to_period('A')) 买家会员名 买家实际支付金额 联系手机 订单付款时间 2018 mrhy50 48.86 1********** 2018 mrhy37 55.86 1********** 2018 mrhy63 79.80 1********** 2018 mrhy79 268.00 1********** 2018 mrhy73 268.00 1********** # 按“季度”显示数据 print(df.to_period('Q')) 买家会员名 买家实际支付金额 联系手机 订单付款时间 2018Q2 mrhy50 48.86 1********** 2018Q2 mrhy37 55.86 1********** 2018Q2 mrhy63 79.80 1********** 2018Q2 mrhy79 268.00 1********** 2018Q2 mrhy73 268.00 1********** # 按“月”显示数据 print(df.to_period('M')) 买家会员名 买家实际支付金额 联系手机 订单付款时间 2018-05 mrhy50 48.86 1********** 2018-05 mrhy37 55.86 1********** 2018-05 mrhy63 79.80 1********** 2018-05 mrhy79 268.00 1********** 2018-05 mrhy73 268.00 1********** # 按“星期”显示数据 print(df.to_period('W')) 买家会员名 买家实际支付金额 联系手机 订单付款时间 2018-04-30/2018-05-06 mrhy50 48.86 1********** 2018-04-30/2018-05-06 mrhy37 55.86 1********** 2018-04-30/2018-05-06 mrhy63 79.80 1********** 2018-04-30/2018-05-06 mrhy79 268.00 1********** 2018-04-30/2018-05-06 mrhy73 268.00 1**********
- 按不同时期统计并显示数据
# 按“年”统计并显示数据 print(df.resample('AS').sum().to_period('A')) 买家实际支付金额 订单付款时间 2018 111219.8
# 按“季度”统计并显示数据 print(df.resample('Q').sum().to_period('Q')) 买家实际支付金额 订单付款时间 2018Q2 18856.07 2018Q3 81803.08 2018Q4 10560.65
# 按“月”统计并显示数据 print(df.resample('M').sum().to_period('M')) 买家实际支付金额 订单付款时间 2018-05 8832.28 2018-06 10023.79 2018-07 33333.24 2018-08 31089.73 2018-09 17380.11 2018-10 10560.65
# 按“星期”统计并显示数据 print(df.resample('W').sum().to_period('W').head(10)) 买家实际支付金额 订单付款时间 2018-04-30/2018-05-06 2430.64 2018-05-07/2018-05-13 1888.76 2018-05-14/2018-05-20 1021.90 2018-05-21/2018-05-27 2858.06 2018-05-28/2018-06-03 1756.38 2018-06-04/2018-06-10 2585.42 2018-06-11/2018-06-17 2466.11 2018-06-18/2018-06-24 2843.64 2018-06-25/2018-07-01 1061.02 2018-07-02/2018-07-08 2497.72
时间序列
- 重采样(Resample 方法)
在 Pandas 中,在时间序列的频率的调整称之为重新采样,即将时间序列从一个频率转换到另一个频率的处理过程。例如,将每1天一个频率,转换为每5天一个频率。
重采样主要使用 resample 方法,该方法用于常规时间序列重新采样和频率转换,包括降采样和升采样。语法如下:
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None)
参数说明:
rule: 字符串,偏移量表示目标字符串或对象转换 how: 用于生产聚合值的函数名或数组函数,例如,“mean”、“ohlc”、“first”、“median” 等 axis: 整型,表示行列。0表示列,1表示行,默认值为0 fill_method: 升采样时所使用的填充方法,ffill方法(用前值填充)或bfill方法(用后值填充),默认值为None closed: 当降采样时,时间区间的开和闭,和数学里区间的概念一样,其值为 “right” 或 “left”。“right” 表示左开右闭;“left” 表示左闭右开,默认值为 “right” 左开右闭 label: 当降采样时,如何设置聚合值的标签。默认值为None convention: 当重采样时,将低频率转换到高频率所采样的约定,其值为 “start” 或 “end”,默认值为 “start” kind: 聚合到时期(“period”)或时间戳(“timestamp”),默认聚合到时间序列的索引类型,默认值为None loffset: 聚合标签的时间校正值,默认值为None。例如,“-1s” 用于将聚合标签调早1秒 limit: 向前或向后填充时,允许填充的最大时期数,默认值为None base: 整型,默认值为0。对于均匀细分1天的频率,聚合间隔的 “原点”。例如,对于 “5min” 频率,base的范围可以是0~4 on: 字符串,可选参数,默认值为None。对DataFrame对象使用列代替索引进行重新采样,列必须与日期时间类似 level: 字符串或整型,可选参数,默认值为None。用于多索引,重新采样的级别名称或级别编号,级别必须与日期时间类似 返回值: 重新采样对象
使用示例:
import pandas as pd index = pd.date_range('02/02/2020',periods=9,freq='T') series = pd.Series(range(9),index=index) # 将1分钟的时间序列转换为3分钟 print(series.resample('3T').sum()) 2020-02-02 00:00:00 3 2020-02-02 00:03:00 12 2020-02-02 00:06:00 21 Freq: 3T, dtype: int64
- 降采样处理
降采样时周期由高频率转向低频率。例如,将 5min 的股票交易转换为日交易;按天统计的销售数据转换为按周统计。
数据降采样会涉及到数据的集合。例如,“天数据” 变成 “周数据”,那么就要对一周7天的数据进行聚合,聚合的方式主要包括求和、求均值等。
import pandas as pd excel_file = r'../../../DataAnalysis/Code/04/50/time.xls' df = pd.read_excel(excel_file) # 设置 “订单付款时间” 为索引 df = df.set_index('订单付款时间') # 按 “周” 统计数据 print(df.resample('W').sum()) 买家实际支付金额 宝贝总数量 订单付款时间 2018-01-07 5735.91 77 2018-01-14 4697.62 70 2018-01-21 5568.77 74 2018-01-28 5408.68 53 2018-02-04 1958.19 19
- 升采样处理
升采样是周期由低频率转向高频率。将数据从低频率转换到高频率时,就不需要聚合了,将其重采样到日频率,默认会引入缺失值。例如,原来是按周统计的数据,现在变成按天统计。
升采样会涉及到数据的填充,根据填充的方法不同,填充的数据也就不同,主要有如下三种填充方法:
- 不填充。空值用 NaN 代替,使用 asfreq 方法
- 用前值填充。用前面的值填充,使用
ffill方法或者pad方法 - 用后值填充。用后面的值填充,使用
bfill方法
import pandas as pd import numpy as np rng = pd.date_range('20200202',periods=2) s1 = pd.Series(np.arange(1,3),index=rng) # 升采样为 “6H” 统计一次数据,空值用 “NaN” 填充 print(s1.resample('6H').asfreq()) 2020-02-02 00:00:00 1.0 2020-02-02 06:00:00 NaN 2020-02-02 12:00:00 NaN 2020-02-02 18:00:00 NaN 2020-02-03 00:00:00 2.0 Freq: 6H, dtype: float64 # 升采样为 “6H” 统计一次数据,空值用 “前值” 填充 print(s1.resample('6H').ffill()) 2020-02-02 00:00:00 1 2020-02-02 06:00:00 1 2020-02-02 12:00:00 1 2020-02-02 18:00:00 1 2020-02-03 00:00:00 2 Freq: 6H, dtype: int64 # 升采样为 “6H” 统计一次数据,空值用 “后值” 填充 print(s1.resample('6H').bfill()) 2020-02-02 00:00:00 1 2020-02-02 06:00:00 2 2020-02-02 12:00:00 2 2020-02-02 18:00:00 2 2020-02-03 00:00:00 2 Freq: 6H, dtype: int64
时间序列数据汇总
在金融领域,经常会看到开盘(open)、收盘(close)、最高价(high)和最低价(low)数据等内容,而在 Pandas 中,经过重新采样的数据也可以实现这样的结果,通过调用 ohlc 函数得到数据汇总结果,即开始值、结束值、最高值和最低值。语法如下:
resample.ohlc()
该函数返回 DataFrame 对象,即每组数据的 open、close、high 和 low 值。
使用示例:
import pandas as pd import numpy as np rng = pd.date_range('2/2/2020',periods=12,freq='T') s1 = pd.Series(np.arange(12),index=rng) print(s1.resample('5min').ohlc()) open high low close 2020-02-02 00:00:00 0 4 0 4 2020-02-02 00:05:00 5 9 5 9 2020-02-02 00:10:00 10 11 10 11
移动窗口数据计算
通过重采样可以得到想要的任何频率的数据, 但是这些数据也只是一个时点的数据。那么就存在这样一个问题: 时点的数据波动较大,某一点的数据就不能很好地表现它本身的特性,于是就有了 “移动窗口” 的概念。简单地说,为了提升数据的可靠性,将某个时点的取值扩大到包含这个点的一段区间,用区间来进行判断,这个就是时间窗口。
在 Pandas 中,可以通过 rolling 函数实现移动窗口数据的计算,语法如下:
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)
参数说明:
window: 时间窗口的大小,有两种形式(int或offset)。如果使用int,则数值表示计算统计量的观测值的数量,即向前几个数据。如果是offset类型,则表示时间窗口的大小 min_periods: 每个窗口最少包含的观测值数量,少于这个值的窗口结果为NA。值可以是int,默认值为None。在offset情况下,默认值为1 center: 把窗口的标签设置为居中。布尔型,默认值为False,居左 win_type: 窗口的类型,截取窗的各种函数。字符串类型,默认值为None on: 可选参数,对于DataFrame对象,是指定要计算移动窗口的列,默认值为None axis: 整型、字符串,默认值为0,即对列进行计算 closed: 定义区间的开闭,支持int类型的窗口。对于offset类型,默认值为right(左开右闭),可以根据情况指定为left(左闭右开) 返回值: 为特定操作而生成的窗口或移动窗口的子类
- 使用
rolling函数计算三天的均值
import pandas as pd index = pd.date_range('20200201','20200215') data = [3,6,7,4,2,1,3,8,9,10,12,15,13,22,14] s1_date = pd.Series(data=data,index=index) # 计算每三天的均值,窗口个数为3 print(s1_date.rolling(3).mean().round(2)) 2020-02-01 NaN 2020-02-02 NaN 2020-02-03 5.33 2020-02-04 5.67 2020-02-05 4.33 2020-02-06 2.33 2020-02-07 2.00 2020-02-08 4.00 2020-02-09 6.67 2020-02-10 9.00 2020-02-11 10.33 2020-02-12 12.33 2020-02-13 13.33 2020-02-14 16.67 2020-02-15 16.33 Freq: D, dtype: float64
- 用当天的数据代表窗口数据
在计算第一个时间点2020-02-01的窗口数据时,虽然数据没有达到窗口长度3,但是至少有当天的数据,通过设置 min_periods 参数即可实现用当天的数据代表窗口数据。它表示窗口中最少包含的观测值,小于这个值的窗口长度显示为空,等于或大于时都将有数值。
import pandas as pd index = pd.date_range('20200201','20200215') data = [3,6,7,4,2,1,3,8,9,10,12,15,13,22,14] s1_date = pd.Series(data=data,index=index) print(s1_date.rolling(3,min_periods=1).mean().round(2)) 2020-02-01 3.00 2020-02-02 4.50 2020-02-03 5.33 2020-02-04 5.67 2020-02-05 4.33 2020-02-06 2.33 2020-02-07 2.00 2020-02-08 4.00 2020-02-09 6.67 2020-02-10 9.00 2020-02-11 10.33 2020-02-12 12.33 2020-02-13 13.33 2020-02-14 16.67 2020-02-15 16.33 Freq: D, dtype: float64
原创文章,转载请注明出处:http://www.opcoder.cn/article/38/